This is a guest blog post written by Nitin Kumar, a Lead Data Scientist at T and T Consulting Services, Inc.
In this post, we discuss the value and potential impact of federated learning in the healthcare field. This approach can help heart stroke patients, doctors, and researchers with faster diagnosis, enriched decision-making, and more informed, inclusive research work on stroke-related health issues, using a cloud-native approach with AWS services for lightweight lift and straightforward adoption.
Diagnosis challenges with heart strokes
Statistics from the Centers for Disease Control and Prevention (CDC) show that each year in the US, more than 795,000 people suffer from their first stroke, and about 25% of them experience recurrent attacks. It is the number five cause of death according to the American Stroke Association and a leading cause of disability in the US. Therefore, it’s crucial to have prompt diagnosis and treatment to reduce brain damage and other complications in acute stroke patients.
CTs and MRIs are the gold standard in imaging technologies for classifying different sub-types of strokes and are crucial during preliminary assessment of patients, determining the root cause, and treatment. One critical challenge here, especially in the case of acute stroke, is the time of imaging diagnosis, which on average ranges from 30 minutes up to an hour and can be much longer depending on emergency department crowding.
Doctors and medical staff need quick and accurate image diagnosis to evaluate a patient’s condition and propose treatment options. In Dr. Werner Vogels’s own words at AWS re:Invent 2023, “every second that a person has a stroke counts.” Stroke victims can lose around 1.9 billion neurons every second they are not being treated.
Medical data restrictions
You can use machine learning (ML) to assist doctors and researchers in diagnosis tasks, thereby speeding up the process. However, the datasets needed to build the ML models and give reliable results are sitting in silos across different healthcare systems and organizations. This isolated legacy data has the potential for massive impact if cumulated. So why hasn’t it been used yet?
There are multiple challenges when working with medical domain datasets and building ML solutions, including patient privacy, security of personal data, and certain bureaucratic and policy restrictions. Additionally, research institutions have been tightening their data sharing practices. These obstacles also prevent international research teams from working together on diverse and rich datasets, which could save lives and prevent disabilities that can result from heart strokes, among other benefits.
Policies and regulations like General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPPA), and California Consumer Privacy Act (CCPA) put guardrails on sharing data from the medical domain, especially patient data. Additionally, the datasets at individual institutes, organizations, and hospitals are often too small, are unbalanced, or have biased distribution, leading to model generalization constraints.
Federated learning: An introduction
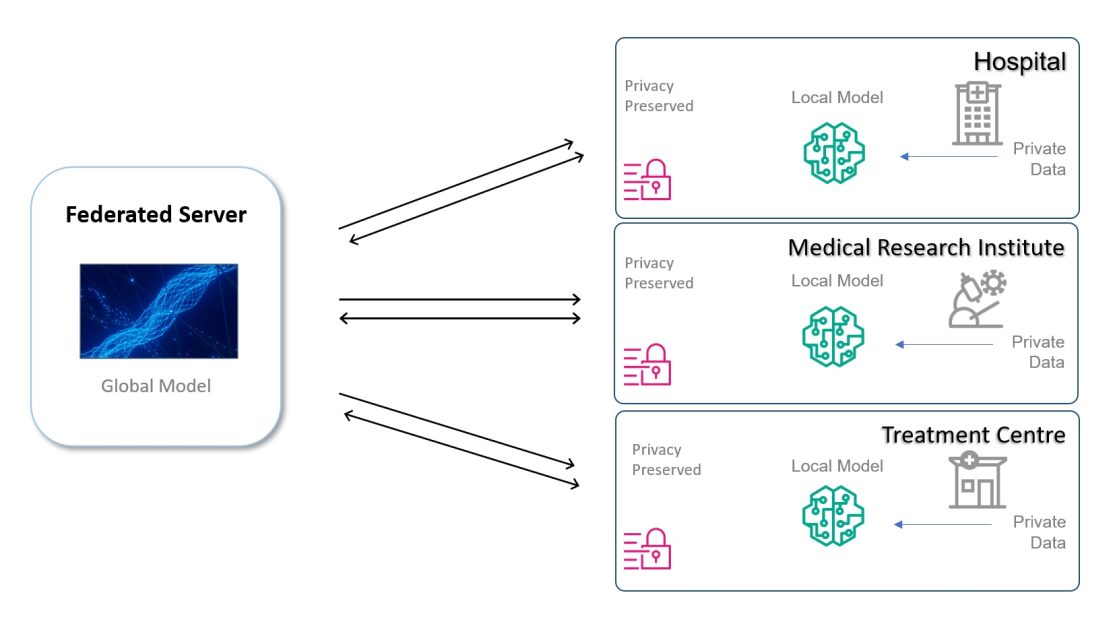
Federated learning (FL) is a decentralized form of ML—a dynamic engineering approach. In this decentralized ML approach, the ML model is shared between organizations for training on proprietary data subsets, unlike traditional centralized ML training, where the model generally trains on aggregated datasets. The data stays protected behind the organization’s firewalls or VPC, while the model with its metadata is shared.
In the training phase, a global FL model is disseminated and synchronized between unit organizations for training on individual datasets, and a local trained model is returned. The final global model is available to use to make predictions for everyone among the participants, and can also be used as a base for further training to build local custom models for participating organizations. It can further be extended to benefit other institutes. This approach can significantly reduce the cybersecurity requirements for data in transit by removing the need for data to transit outside of the organization’s boundaries at all.
The following diagram illustrates an example architecture.
In the following sections, we discuss how federated learning can help.
Federation learning to save the day (and save lives)
For good artificial intelligence (AI), you need good data.
Legacy systems, which are frequently found in the federal domain, pose significant data processing challenges before you can derive any intelligence or merge them with newer datasets. This is an obstacle in providing valuable intelligence to leaders. It can lead to inaccurate decision-making because the proportion of legacy data is sometimes much more valuable compared to the newer small dataset. You want to resolve this bottleneck effectively and without workloads of manual consolidation and integration efforts (including cumbersome mapping processes) for legacy and newer datasets sitting across hospitals and institutes, which can take many months—if not years, in many cases. The legacy data is quite valuable because it holds important contextual information needed for accurate decision-making and well-informed model training, leading to reliable AI in the real world. Duration of data informs on long-term variations and patterns in the dataset that would otherwise go undetected and lead to biased and ill-informed predictions.
Breaking down these data silos to unite the untapped potential of the scattered data can save and transform many lives. It can also accelerate the research related to secondary health issues arising from heart strokes. This solution can help you share insights from data isolated between institutes due to policy and other reasons, whether you are a hospital, a research institute, or other health data-focused organizations. It can enable informed decisions on research direction and diagnosis. Additionally, it results in a centralized repository of intelligence via a secure, private, and global knowledge base.

Federated learning has many benefits in general and specifically for medical data settings.
Security and Privacy features:
- Keeps sensitive data away from the internet and still uses it for ML, and harnesses its intelligence with differential privacy
- Enables you to build, train, and deploy unbiased and robust models across not just machines but also networks, without any data security hazards
- Overcomes the hurdles with multiple vendors managing the data
- Eliminates the need for cross-site data sharing and global governance
- Preserves privacy with differential privacy and offers secure multi-party computation with local training
Performance Improvements:
- Addresses the small sample size problem in the medical imaging space and costly labeling processes
- Balances the distribution of the data
- Enables you to incorporate most traditional ML and deep learning (DL) methods
- Uses pooled image sets to help improve statistical power, overcoming the sample size limitation of individual institutions
Resilience Benefits:
- If any one party decides to leave, it won’t hinder the training
- A new hospital or institute can join at any time; it’s not reliant on any specific dataset with any node organization
- There is no need for extensive data engineering pipelines for the legacy data scattered across widespread geographical locations
These features can help bring the walls down between institutions hosting isolated datasets on similar domains. The solution can become a force multiplier by harnessing the unified powers of distributed datasets and improving efficiency by radically transforming the scalability aspect without the heavy infrastructure lift. This approach helps ML reach its full potential, becoming proficient at the clinical level and not just research.
Federated learning has comparable performance to regular ML, as shown in the following experiment by NVidia Clara (on Medical Modal ARchive (MMAR) using the BRATS2018 dataset). Here, FL achieved a comparable segmentation performance compared to training with centralized data: over 80% with approximately 600 epochs while training a multi-modal, multi-class brain tumor segmentation task.
Federated learning has been tested recently in a few medical sub-fields for use cases including patient similarity learning, patient representation learning, phenotyping, and predictive modeling.
Application blueprint: Federated learning makes it possible and straightforward
To get started with FL, you can choose from many high-quality datasets. For example, datasets with brain images include ABIDE (Autism Brain Imaging Data Exchange initiative), ADNI (Alzheimer’s Disease Neuroimaging Initiative), RSNA (Radiological Society of North America) Brain CT, BraTS (Multimodal Brain Tumor Image Segmentation Benchmark) updated regularly for the Brain Tumor Segmentation Challenge under UPenn (University of Pennsylvania), UK BioBank (covered in the following NIH paper), and IXI. Similarly for heart images, you can choose from several publicly available options, including ACDC (Automatic Cardiac Diagnosis Challenge), which is a cardiac MRI assessment dataset with full annotation mentioned by the National Library of Medicine in the following paper, and M&M (Multi-Center, Multi-Vendor, and Multi-Disease) Cardiac Segmentation Challenge mentioned in the following IEEE paper.
The following images show a probabilistic lesion overlap map for the primary lesions from the ATLAS R1.1 dataset. (Strokes are one of the most common causes of brain lesions according to Cleveland Clinic.)

For Electronic Health Records (EHR) data, a few datasets are available that follow the Fast Healthcare Interoperability Resources (FHIR) standard. This standard helps you build straightforward pilots by removing certain challenges with heterogenous, non-normalized datasets, allowing for seamless and secure exchange, sharing, and integration of datasets. The FHIR enables maximum interoperability. Dataset examples include MIMIC-IV (Medical Information Mart for Intensive Care). Other good-quality datasets that aren’t currently FHIR but can be easily converted include Centers for Medicare & Medicaid Services (CMS) Public Use Files (PUF) and eICU Collaborative Research Database from MIT (Massachusetts Institute of Technology). There are also other resources becoming available that offer FHIR-based datasets.
The lifecycle for implementing FL can include the following steps: task initialization, selection, configuration, model training, client/server communication, scheduling and optimization, versioning, testing, deployment, and termination. There are many time-intensive steps that go into preparing medical imaging data for traditional ML, as described in the following paper. Domain knowledge might be needed in some scenarios to preprocess raw patient data, especially due to its sensitive and private nature. These can be consolidated and sometimes eliminated for FL, saving crucial time for training and providing faster results.
Implementation
FL tools and libraries have grown with widespread support, making it straightforward to use FL without a heavy overhead lift. There are a lot of good resources and framework options available to get started. You can refer to the following extensive list of the most popular frameworks and tools in the FL domain, including PySyft, FedML, Flower, OpenFL, FATE, TensorFlow Federated, and NVFlare. It provides a beginner’s list of projects to get started quickly and build upon.
You can implement a cloud-native approach with Amazon SageMaker that seamlessly works with AWS VPC peering, keeping each node’s training in a private subnet in their respective VPC and enabling communication via private IPv4 addresses. Furthermore, model hosting on Amazon SageMaker JumpStart can help by exposing the endpoint API without sharing model weights.
It also takes away potential high-level compute challenges with on-premises hardware with Amazon Elastic Compute Cloud (Amazon EC2) resources. You can implement the FL client and servers on AWS with SageMaker notebooks and Amazon Simple Storage Service (Amazon S3), maintain regulated access to the data and model with AWS Identity and Access Management (IAM) roles, and use AWS Security Token Service (AWS STS) for client-side security. You can also build your own custom system for FL using Amazon EC2.
For a detailed overview of implementing FL with the Flower framework on SageMaker, and a discussion of its difference from distributed training, refer to Machine learning with decentralized training data using federated learning on Amazon SageMaker.
The following figures illustrate the architecture of transfer learning in FL.
![]()
Addressing FL data challenges
Federated learning comes with its own data challenges, including privacy and security, but they are straightforward to address. First, you need to address the data heterogeneity problem with medical imaging data arising from data being stored across different sites and participating organizations, known as a domain shift problem (also referred to as client shift in an FL system), as highlighted by Guan and Liu in the following paper. This can lead to a difference in convergence of the global model.
Other components for consideration include ensuring data quality and uniformity at the source, incorporating expert knowledge into the learning process to inspire confidence in the system among medical professionals, and achieving model precision. For more information about some of the potential challenges you may face during implementation, refer to the following paper.
AWS helps you resolve these challenges with features like the flexible compute of Amazon EC2 and pre-built Docker images in SageMaker for straightforward deployment. You can resolve client-side problems like unbalanced data and computation resources for each node organization. You can address server-side learning problems like poisoning attacks from malicious parties with Amazon Virtual Private Cloud (Amazon VPC), security groups, and other security standards, preventing client corruption and implementing AWS anomaly detection services.
AWS also helps in addressing real-world implementation challenges, which can include integration challenges, compatibility issues with current or legacy hospital systems, and user adoption hurdles, by offering flexible, easy-to-use, and effortless lift tech solutions.
With AWS services, you can enable large-scale FL-based research and clinical implementation and deployment, which can consist of various sites across the world.
Recent policies on interoperability highlight the need for federated learning
Many laws recently passed by the government include a focus on data interoperability, bolstering the need for cross-organizational interoperability of data for intelligence. This can be fulfilled by using FL, including frameworks like the TEFCA (Trusted Exchange Framework and Common Agreement) and the expanded USCDI (United States Core Data for Interoperability).
The proposed idea also contributes towards the CDC’s capture and distribution initiative CDC Moving Forward. The following quote from the GovCIO article Data Sharing and AI Top Federal Health Agency Priorities in 2024 also echoes a similar theme: “These capabilities can also support the public in an equitable way, meeting patients where they are and unlocking critical access to these services. Much of this work comes down to the data.”
This can help medical institutes and agencies around the country (and across the globe) with data silos. They can benefit from seamless and secure integration and data interoperability, making medical data usable for impactful ML-based predictions and pattern recognition. You can start with images, but the approach is applicable to all EHR as well. The goal is to find the best approach for data stakeholders, with a cloud-native pipeline to normalize and standardize the data or directly use it for FL.
Let’s explore an example use case. Heart stroke imaging data and scans are scattered around the country and the world, sitting in isolated silos in institutes, universities, and hospitals, and separated by bureaucratic, geographical, and political boundaries. There is no single aggregated source and no easy way for medical professionals (non-programmers) to extract insights from it. At the same time, it’s not feasible to train ML and DL models on this data, which could help medical professionals make faster, more accurate decisions in critical times when heart scans can take hours to come in while the patient’s life could be hanging in the balance.
Other known use cases include POTS (Purchasing Online Tracking System) at NIH (National Institutes of Health) and cybersecurity for scattered and tiered intelligence solution needs at COMCOMs/MAJCOMs locations around the globe.
Conclusion
Federated learning holds great promise for legacy healthcare data analytics and intelligence. It’s straightforward to implement a cloud-native solution with AWS services, and FL is especially helpful for medical organizations with legacy data and technical challenges. FL can have a potential impact on the entire treatment cycle, and now even more so with the focus on data interoperability from large federal organizations and government leaders.
This solution can help you avoid reinventing the wheel and use the latest technology to take a leap from legacy systems and be at the forefront in this ever-evolving world of AI. You can also become a leader for best practices and an efficient approach to data interoperability within and across agencies and institutes in the health domain and beyond. If you are an institute or agency with data silos scattered around the country, you can benefit from this seamless and secure integration.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post. It is each customers’ responsibility to determine whether they are subject to HIPAA, and if so, how best to comply with HIPAA and its implementing regulations. Before using AWS in connection with protected health information, customers must enter an AWS Business Associate Addendum (BAA) and follow its configuration requirements.
About the Author

Nitin Kumar (MS, CMU) is a Lead Data Scientist at T and T Consulting Services, Inc. He has extensive experience with R&D prototyping, health informatics, public sector data, and data interoperability. He applies his knowledge of cutting-edge research methods to the federal sector to deliver innovative technical papers, POCs, and MVPs. He has worked with multiple federal agencies to advance their data and AI goals. Nitin’s other focus areas include natural language processing (NLP), data pipelines, and generative AI.