Image by Author
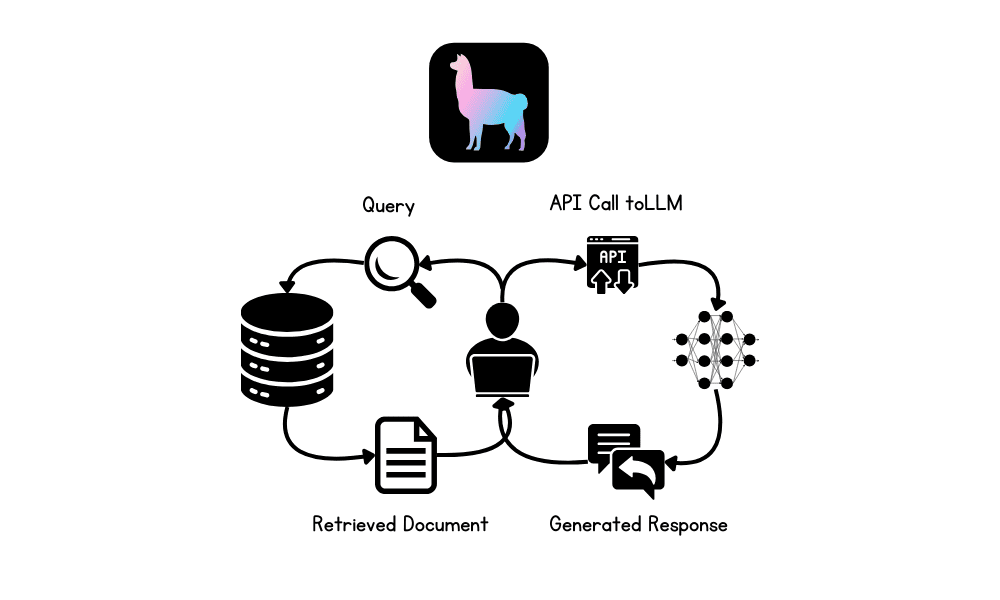
In this tutorial, we will explore Retrieval-Augmented Generation (RAG) and the LlamaIndex AI framework. We will learn how to use LlamaIndex to build a RAG-based application for Q&A over the private documents and enhance the application by incorporating a memory buffer. This will enable the LLM to generate the response using the context from both the document and previous interactions.
What is RAG in LLMs?
Retrieval-Augmented Generation (RAG) is an advanced methodology designed to enhance the performance of large language models (LLMs) by integrating external knowledge sources into the generation process.
RAG involves two main phases: retrieval and content generation. Initially, relevant documents or data are retrieved from external databases, which are then used to provide context for the LLM, ensuring that responses are based on the most current and domain-specific information available.
What is LlamaIndex?
LlamaIndex is an advanced AI framework that is designed to enhance the capabilities of large language models (LLMs) by facilitating seamless integration with diverse data sources. It supports the retrieval of data from over 160 different formats, including APIs, PDFs, and SQL databases, making it highly versatile for building advanced AI applications.
We can even build a complete multimodal and multistep AI application and then deploy it to a server to provide highly accurate, domain-specific responses. Compared to other frameworks like LangChain, LlamaIndex offers a simpler solution with built-in functions tailored for various types of LLM applications.
Building RAG Applications using LlamaIndex
In this section, we will build an AI application that loads Microsoft Word files from a folder, converts them into embeddings, indexes them into the vector store, and builds a simple query engine. After that, we will build a proper RAG chatbot with history using vector store as a retriever, LLM, and the memory buffer.
Setting up
Install all the necessary Python packages to load the data and for OpenAI API.
|
!pip install llama–index !pip install llama–index–embeddings–openai !pip install llama–index–llms–openai !pip install llama–index–readers–file !pip install docx2txt |
Initiate LLM and embedding model using OpenAI functions. We will use the latest “GPT-4o” and “text-embedding-3-small” models.
|
from llama_index.llms.openai import OpenAI from llama_index.embeddings.openai import OpenAIEmbedding
# initialize the LLM llm = OpenAI(model=“gpt-4o”)
# initialize the embedding embed_model = OpenAIEmbedding(model=“text-embedding-3-small”) |
Set both LLM and embedding model to global so that when we invoke a function that requires LLM or embeddings, it will automatically use these settings.
|
from llama_index.core import Settings
# global settings Settings.llm = llm Settings.embed_model = embed_model |
Loading and Indexing the Documents
Load the data from the folder, convert it into the embedding, and store it into the vector store.
|
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# load documents data = SimpleDirectoryReader(input_dir=“/work/data/”,required_exts=[“.docx”]).load_data()
# indexing documents using vector store index = VectorStoreIndex.from_documents(data) |
Building Query Engine
Please convert the vector store to a query engine and begin asking questions about the documents. The documents consist of the blogs published in June on Machine Learning Mastery by the author Abid Ali Awan.
|
from llama_index.core <b>import</b> VectorStoreIndex
# converting vector store to query engine query_engine = index.as_query_engine(similarity_top_k=3)
# generating query response response = query_engine.query(“What are the common themes of the blogs?”) print(response) |
And the answer is accurate.
The common themes of the blogs are centered around enhancing knowledge and skills in machine learning. They focus on providing resources such as free books, platforms for collaboration, and datasets to help individuals deepen their understanding of machine learning algorithms, collaborate effectively on projects, and gain practical experience through real-world data. These resources are aimed at both beginners and professionals looking to build a strong foundation and advance their careers in the field of machine learning.
Building RAG Application with Memory Buffer
The previous app was simple; let’s create a more advanced chatbot with a history feature.
We will build the chatbot using a retriever, a chat memory buffer, and a GPT-4o model.
Afterward, we will test our chatbot by asking questions about one of the blog posts.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
from llama_index.core.memory import ChatMemoryBuffer from llama_index.core.chat_engine import CondensePlusContextChatEngine
# creating chat memory buffer memory = ChatMemoryBuffer.from_defaults(token_limit=4500)
# creating chat engine chat_engine = CondensePlusContextChatEngine.from_defaults( index.as_retriever(), memory=memory, llm=llm )
# generating chat response response = chat_engine.chat( “What is the one best course for mastering Reinforcement Learning?” ) print(str(response)) |
It is highly accurate and to the point.
Based on the provided documents, the “Deep RL Course” by Hugging Face is highly recommended for mastering Reinforcement Learning. This course is particularly suitable for beginners and covers both the basics and advanced techniques of reinforcement learning. It includes topics such as Q-learning, deep Q-learning, policy gradients, ML agents, actor-critic methods, multi-agent systems, and advanced topics like RLHF (Reinforcement Learning from Human Feedback), Decision Transformers, and MineRL. The course is designed to be completed within a month and offers practical experimentation with models, strategies to improve scores, and a leaderboard to track progress.
Let’s ask follow-up questions and understand more about the course.
|
response = chat_engine.chat( “Tell me more about the course” ) print(str(response)) |
If you are having trouble running the above code, please refer to the Deepnote Notebook: Building RAG Application using LlamaIndex.
Conclusion
Building and deploying AI applications has been made easy by LlamaIndex. You just have to write a few lines of code and that’s it.
The next step in your learning journey will be to build a proper Chatbot application using Gradio and deploy it on the server. To simplify your life even more, you can also check out Llama Cloud.
In this tutorial, we learned about LlamaIndex and how to build an RAG application that lets you ask questions from your private documentation. Then, we built a proper RAG chatbot that generates responses using private documents and previous chat interactions.
Get Started on The Beginner’s Guide to Data Science!

Learn the mindset to become successful in data science projects
…using only minimal math and statistics, acquire your skill through short examples in Python
Discover how in my new Ebook:
The Beginner’s Guide to Data Science
It provides self-study tutorials with all working code in Python to turn you from a novice to an expert. It shows you how to find outliers, confirm the normality of data, find correlated features, handle skewness, check hypotheses, and much more…all to support you in creating a narrative from a dataset.