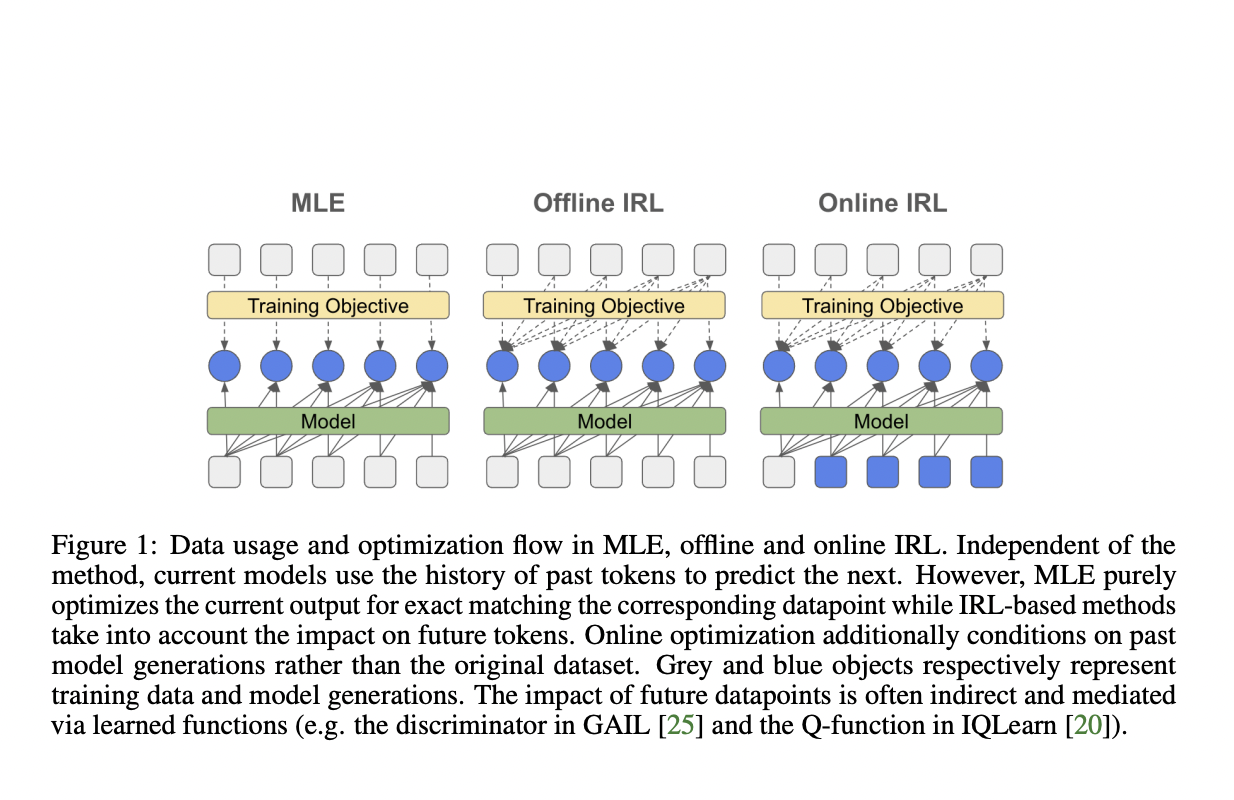
Large language models (LLMs) have gained significant attention in the field of artificial intelligence, primarily due to their ability to imitate human knowledge through extensive datasets. The current methodologies for training these models heavily rely on imitation learning, particularly next token prediction using maximum likelihood estimation (MLE) during pretraining and supervised fine-tuning phases. However, this approach faces several challenges, including compounding errors in autoregressive models, exposure bias, and distribution shifts during iterative model application. These issues become more pronounced with longer sequences, potentially leading to degraded performance and misalignment with human intent. As the field progresses, there is a growing need to address these challenges and develop more effective methods for training and aligning LLMs with human preferences and intentions.
Existing attempts to address the challenges in language model training have primarily focused on two main approaches: behavioral cloning (BC) and inverse reinforcement learning (IRL). BC, analogous to supervised fine-tuning via MLE, directly mimics expert demonstrations but suffers from compounding errors and requires extensive data coverage. IRL, on the other hand, jointly infers the policy and reward function, potentially overcoming BC’s limitations by utilizing additional environment interactions. Recent IRL methods have incorporated game-theoretic approaches, entropy regularization, and various optimization techniques to improve stability and scalability. In the context of language modeling, some researchers have explored adversarial training methods, such as SeqGAN, as alternatives to MLE. However, these approaches have shown limited success, working effectively only in specific temperature regimes. Despite these efforts, the field continues to seek more robust and scalable solutions for training and aligning large language models.
DeepMind researchers propose an in-depth investigation of RL-based optimization, particularly focusing on the distribution matching perspective of IRL, for fine-tuning large language models. This approach aims to provide an effective alternative to standard MLE. The study encompasses both adversarial and non-adversarial methods, as well as offline and online techniques. A key innovation is the extension of inverse soft Q-learning to establish a principled connection with classical behavior cloning or MLE. The research evaluates models ranging from 250M to 3B parameters, including encoder-decoder T5 and decoder-only PaLM2 architectures. By examining task performance and generation diversity, the study seeks to demonstrate the benefits of IRL over behavior cloning in imitation learning for language models. In addition to that, the research explores the potential of IRL-obtained reward functions to bridge the gap with later stages of RLHF.
The proposed methodology introduces a unique approach to language model fine-tuning by reformulating inverse soft Q-learning as a temporal difference regularized extension of MLE. This method bridges the gap between MLE and algorithms that exploit the sequential nature of language generation.
The approach models language generation as a sequential decision-making problem, where generating the next token is conditioned on the previously generated sequence. The researchers focus on minimizing the divergence between the γ-discounted state-action distribution of the policy and that of the expert policy, combined with a weighted causal entropy term.
The formulation uses the χ2-divergence and rescales the value function, resulting in the IQLearn objective:
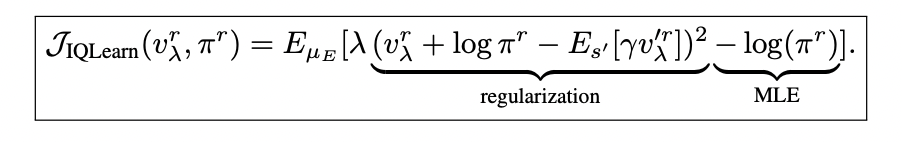
This objective consists of two main components:
1. A regularization term that couples the learned policy to a value function, favoring policies where the log probability of actions matches the difference in state values.
2. An MLE term that maintains the connection to traditional language model training.
Importantly, this formulation allows for annealing of the regularization term, providing flexibility in balancing between standard MLE (λ = 0) and stronger regularization. This approach enables offline training using only expert samples, potentially improving computational efficiency in large-scale language model fine-tuning.
The researchers conducted extensive experiments to evaluate the effectiveness of IRL methods compared to MLE for fine-tuning large language models. Their results demonstrate several key findings:
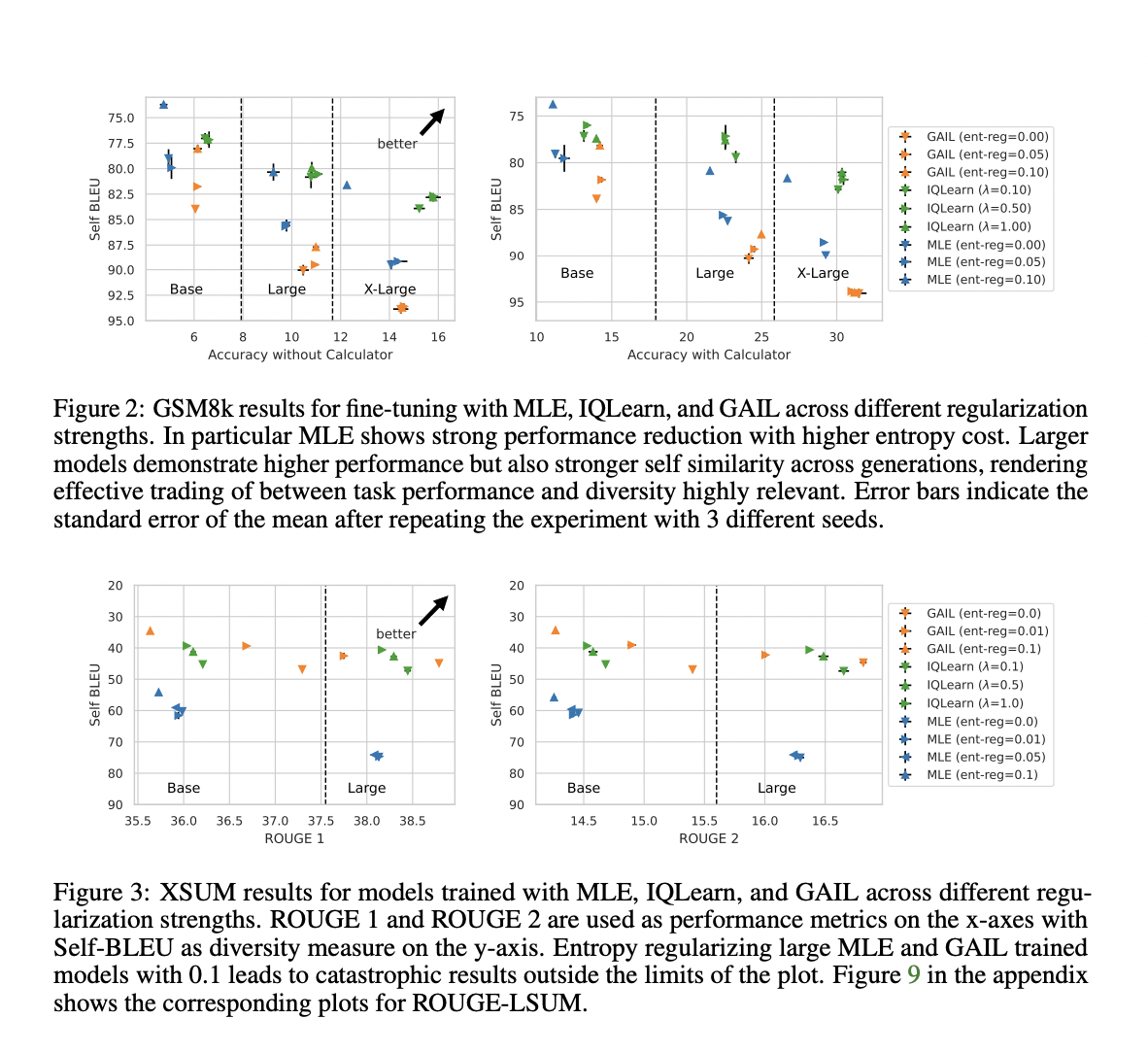
1. Performance improvements: IRL methods, particularly IQLearn, showed small but notable gains in task performance across various benchmarks, including XSUM, GSM8k, TLDR, and WMT22. These improvements were especially pronounced for math and reasoning tasks.
2. Diversity enhancement: IQLearn consistently produced more diverse model generations compared to MLE, as measured by lower Self-BLEU scores. This indicates a better trade-off between task performance and output diversity.
3. Model scalability: The benefits of IRL methods were observed across different model sizes and architectures, including T5 (base, large, and xl) and PaLM2 models.
4. Temperature sensitivity: For PaLM2 models, IQLearn achieved higher performance in low-temperature sampling regimes across all tested tasks, suggesting improved stability in generation quality.
5. Reduced beam search dependency: IQLearn demonstrated the ability to reduce reliance on beam search during inference while maintaining performance, potentially offering computational efficiency gains.
6. GAIL performance: While stabilized for T5 models, GAIL proved challenging to implement effectively for PaLM2 models, highlighting the robustness of the IQLearn approach.
These results suggest that IRL methods, particularly IQLearn, provide a scalable and effective alternative to MLE for fine-tuning large language models, offering improvements in both task performance and generation diversity across a range of tasks and model architectures.
This paper investigates the potential of IRL algorithms for language model fine-tuning, focusing on performance, diversity, and computational efficiency. The researchers introduce a reformulated IQLearn algorithm, enabling a balanced approach between standard supervised fine-tuning and advanced IRL methods. Experiments reveal significant improvements in the trade-off between task performance and generation diversity using IRL. The study majorly demonstrates that computationally efficient offline IRL achieves substantial performance gains over MLE-based optimization without requiring online sampling. Also, the correlation analysis between IRL-extracted rewards and performance metrics suggests the potential for developing more accurate and robust reward functions in language modeling, paving the way for improved language model training and alignment.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.