Natural Language Generation Inside Out: Teaching Machines to Write Like Humans
Image by Editor | Midjourney
Natural language generation (NLG) is an enthralling area of artificial intelligence (AI), or more specifically of natural language processing (NLP), aimed at enabling machines to produce human-like text that drives human-machine communication for problem-solving. This article explores what NLG is, how it works, and how this area has evolved over recent years while underscoring its significance in several applications.
Understanding Natural Language Generation
AI and computer systems in general do not operate on human language but on numerical representations of data. Therefore, NLG involves transforming data that is being processed into human-readable text. Common use cases of NLG include automated report writing, chatbots, question-answering, and personalized content creation.
To better comprehend how NLG works, it is essential to also understand its relationship with natural language understanding (NLU): NLG focuses on producing language, whereas NLU focuses on interpreting and understanding it. Hence, the reverse transformation process to that occurring in NLG takes place in NLU: human language inputs like text must be encoded into numerical — often vector — representations of the text that algorithms and models can analyze, interpret, and make sense of by finding complex language patterns within the text.
At its core, NLG can be understood as a recipe. Just as a chef puts together ingredients in a specific order to create a dish, NLG systems assemble elements of language based on input data such as a prompt, and context information.
It is important to understand that recent NLG approaches like the transformer architecture described later, combine information in inputs by incorporating NLU steps into the initial stages of NLG. Generating a response typically requires understanding an input request or prompt formulated by the user. Once this understanding process is applied and language pieces of the jigsaw are meaningfully assembled, an NLG system generates an output response word by word. This means the output language is not generated entirely at once, but one word after another. In other words, the broader language generation problem is decomposed into a sequence of simpler problems, namely a next-word prediction problem, which is addressed iteratively and sequentially.
The next-word prediction problem is formulated at a low architecture level as a classification task. Just like a conventional classification model in machine learning can be trained to classify pictures of animals into species, or bank customers into eligible or not eligible for a loan, an NLG model incorporates at its final stage a classification layer that estimates the likelihood of each word in a vocabulary or language being the next word the system should generate as part of the message: thus, the highest-likelihood word is returned as the actual next word.
The encoder-decoder transformer architecture is the foundation of modern large language models (LLMs), which excel at NLG tasks. At the final stage of the decoder stack (top-right corner of the diagram below) is a classification layer trained to learn how to predict the next word to generate.
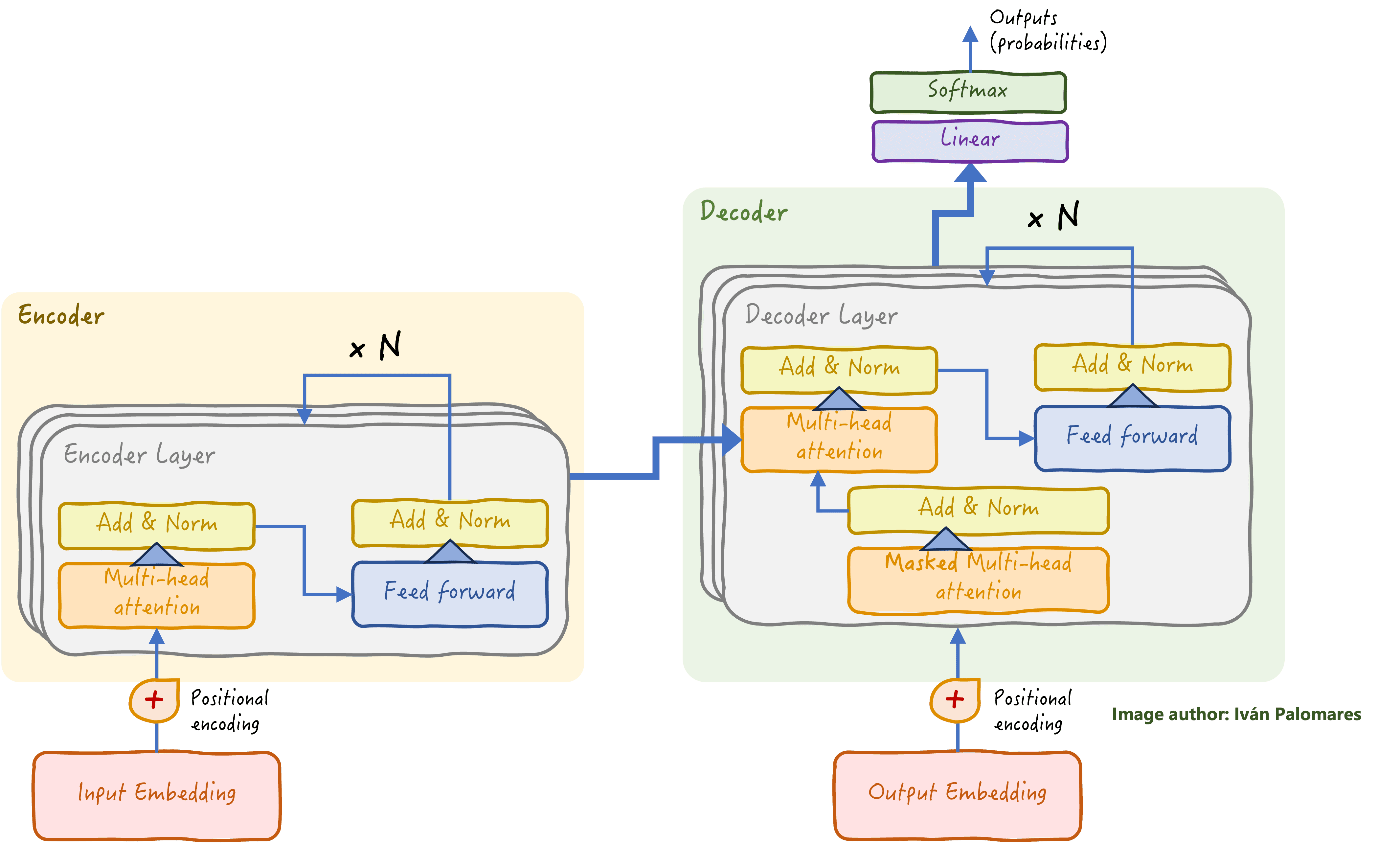
Classical transformer architecture: the encoder stack focuses on language understanding of the input, whereas the decoder stack uses the insight gained to generate a response word by word.
Evolution of NLG Techniques and Architectures
NLG has evolved significantly, from limited and rather static rule-based systems in the early days of NLP to sophisticated models like Transformers and LLMs nowadays, capable of performing an impressive range of language tasks including not only human language but also code generation. The relatively recent introduction of retrieval-augmented generation (RAG) has further enhanced NLG capabilities, addressing some limitations of LLMs like hallucinations and data obsolescence by integrating external knowledge as additional contextual inputs for the generation process. RAG helped enable more relevant and context-aware responses expressed in human language, by retrieving in real-time relevant information to enrich the user’s input prompts.
Trends, Challenges, and Future Directions
The future of NLG looks promising, even though it is not exempt from challenges such as:
- Ensuring accuracy in generated text: as models’ sophistication and complexity grow, ensuring that they generate factually correct and contextually appropriate content remains a key priority for AI developers.
- Ethical considerations: it is essential to tackle issues like bias in generated text and the potential for misuse or illegal uses, requiring more solid frameworks for responsible AI deployment.
- Cost of training and building models: the significant computational resources needed for training state-of-the-art NLG models like those based on transformers, can be a barrier for many organizations, limiting their accessibility. Cloud providers and major AI firms are gradually introducing in the market solutions to eliminate this burden.
As AI technologies continue to expand, we can expect more advanced and intuitive NLG that keep blurring the boundaries between human and machine-driven communication.
About Iván Palomares Carrascosa
Iván Palomares Carrascosa is a leader, writer, speaker, and adviser in AI, machine learning, deep learning & LLMs. He trains and guides others in harnessing AI in the real world.
