Large language models can enable fluent text generation, emergent problem-solving, and creative generation of prose and code. In contrast, vision-language models enable open-vocabulary visual recognition and can even make complex inferences about object-agent interactions in images. The best way for robots to learn new skills needs to be clarified. Compared to the billions of tokens and photos used to train the most advanced language and vision-language models on the web, the amount of data collected from robots is unlikely to be comparable. However, it is also challenging to immediately adapt such models to robotic activities since these models reason about semantics, labels, and textual prompts. In contrast, robots must be instructed in low-level actions, such as those using the Cartesian end-effector.
Google Deepmind’s research aims to improve generalization and enable emergent semantic reasoning by directly incorporating vision-language models trained on Internet-scale data into end-to-end robotic control. With the help of web-based language and vision-language data, we aim to make a single, comprehensively trained model to learn to link robot observations to actions. They propose fine-tuning state-of-the-art vision-language models together using data from robot trajectories and large-scale visual question-answering exercises conducted over the Internet. In contrast to other methods, they propose a straightforward, all-purpose recipe: express robotic actions as text tokens and incorporate them directly into the model’s training set as natural language tokens would. Researchers study vision-language-action models (VLA), and RT-2 instantiates one such model. Through rigorous testing (6k assessment trials), they could ascertain that RT-2 acquired various emergent skills through Internet-scale training and that the technique led to performant robotic policies.
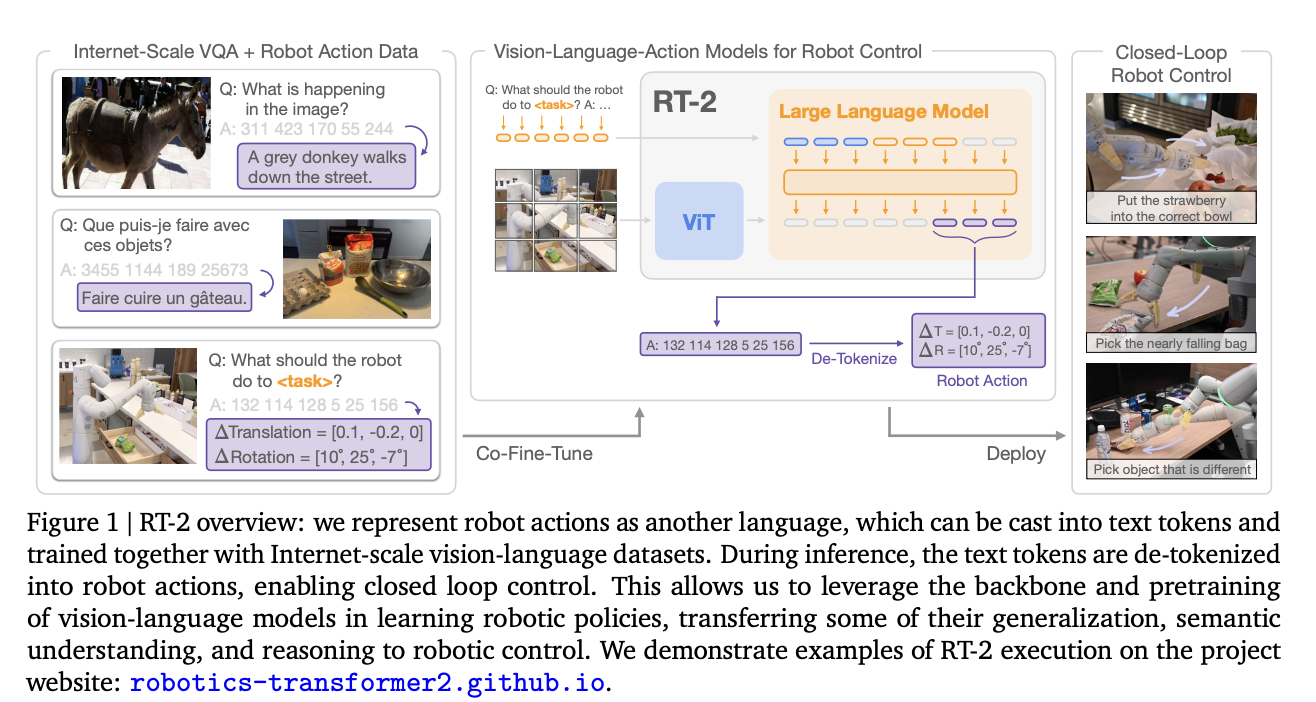
Google DeepMind unveiled RT-2, a Transformer-based model trained on the web-sourced text and images that can directly perform robotic operations, as a follow-up to its Robotics Transformer model 1. They use robot actions to represent a second language that can be converted into text tokens and taught alongside large-scale vision-language datasets available online. Inference involves de-tokenizing text tokens into robot behaviors that can then be controlled via a feedback loop. This permits transferring some of the generalization, semantic comprehension, and reasoning of vision-language models to learning robotic policies. On the project website, accessible at https://robotics-transformer2.github.io/, the team behind RT-2 provides live demonstrations of its use.
The model retains the ability to deploy its physical skills in ways consistent with the distribution found in the robot data. Still, it also learns to use those skills in novel contexts by reading visuals and linguistic commands using knowledge gathered from the web. Even though semantic cues like precise numbers or icons aren’t included in the robot data, the model can repurpose its learned pick-and-place skills. No such relations were supplied in the robot demos, yet the model could pick the correct object and position it in the correct location. In addition, the model can make even more complex semantic inferences if the command is supplemented with a chain of thought prompting, such as knowing that a rock is the best choice for an improvised hammer or an energy drink is the best choice for someone tired.
Google DeepMind’s key contribution is RT-2, a family of models created by fine-tuning huge vision-language models trained on web-scale data to serve as generalizable and semantically aware robotic rules. Experiments probe models with as much as 55B parameters, learned from publicly available data and annotated with robotic motion commands. Across 6,000 robotic evaluations, they demonstrate that RT-2 enables considerable advances in generalization over objects, scenes, and instructions and displays a range of emergent abilities that are a byproduct of web-scale vision-language pretraining.
Key Features
- The reasoning, symbol interpretation, and human identification capabilities of RT-2 can be used in a wide range of practical scenarios.
- The results of RT-2 demonstrate that pretraining VLMs using robotic data can turn them into powerful vision-language-action (VLA) models that can directly control a robot.
- A promising direction to pursue is to construct a general-purpose physical robot that can think, problem-solve, and interpret information for completing various activities in the actual world, like RT-2.
- Its adaptability and efficiency in handling various tasks are displayed in RT-2’s capacity to transfer information from language and visual training data to robot movements.
Limitations
Despite its encouraging generalization properties, RT-2 suffers from several drawbacks. Although studies suggest that incorporating web-scale pretraining through VLMs improves generalization across semantic and visual concepts, this does not give the robot any new abilities regarding its capacity to perform motions. Though the model can only use the physical abilities found in the robot data in novel ways, it does learn to make better use of its abilities. They attribute this to a need for more diversity in the sample along the dimensions of competence. New data-gathering paradigms, such as films of humans, present an intriguing opportunity for future research into acquiring new skills.
To sum it up, Google DeepMind researchers demonstrated that big VLA models could be run in real-time, but this was at a considerable computational expense. As these methods are applied to situations requiring high-frequency control, real-time inference risks become a significant bottleneck. Quantization and distillation approaches that could let such models operate faster or on cheaper hardware are attractive areas for future study. This is related to another existing restriction in that relatively few VLM models can be utilized to develop RT-2.
Researchers from Google DeepMind summarized the process of training vision-language-action (VLA) models by integrating pretraining with vision-language models (VLMs) and data from robotics. They then introduced two variants of VLAs (RT-2-PaLM-E and RT-2-PaLI-X) that PaLM-E and PaLI-X, respectively inspired. These models are fine-tuned with data on robotic trajectories to generate robot actions, which are tokenized as text. More crucially, they demonstrated that the technique improves generalization performance and emergent capabilities inherited from web-scale vision-language pretraining, leading to very effective robotic policies. According to Google DeepMind, the discipline of robot learning is now strategically positioned to profit from improvements in other fields thanks to this straightforward and universal methodology.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 27k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.