MLOps is a key discipline that often oversees the path to productionizing machine learning (ML) models. It’s natural to focus on a single model that you want to train and deploy. However, in reality, you’ll likely work with dozens or even hundreds of models, and the process may involve multiple complex steps. Therefore, it’s important to have the infrastructure in place to track, train, deploy, and monitor models with varying complexities at scale. This is where MLOps tooling comes in. MLOps tooling helps you repeatably and reliably build and simplify these processes into a workflow that is tailored for ML.
Amazon SageMaker Pipelines, a feature of Amazon SageMaker, is a purpose-built workflow orchestration service for ML that helps you automate end-to-end ML workflows at scale. It simplifies the development and maintenance of ML models by providing a centralized platform to orchestrate tasks such as data preparation, model training, tuning and validation. SageMaker Pipelines can help you streamline workflow management, accelerate experimentation and retrain models more easily.
In this post, we spotlight an exciting new feature of SageMaker Pipelines known as Selective Execution. This new feature empowers you to selectively run specific portions of your ML workflow, resulting in significant time and compute resource savings by limiting the run to pipeline steps in scope and eliminating the need to run steps out of scope. Furthermore, we explore various use cases where the advantages of utilizing Selective Execution become evident, further solidifying its value proposition.
Solution overview
SageMaker Pipelines continues to innovate its developer experience with the release of Selective Execution. ML builders now have the ability to choose specific steps to run within a pipeline, eliminating the need to rerun the entire pipeline. This feature enables you to rerun specific sections of the pipeline while modifying the runtime parameters associated with the selected steps.
It’s important to note that the selected steps may rely on the results of non-selected steps. In such cases, the outputs of these non-selected steps are reused from a reference run of the current pipeline version. This means that the reference run must have already completed. The default reference run is the latest run of the current pipeline version, but you can also choose to use a different run of the current pipeline version as a reference.
The overall state of the reference run must be Successful, Failed or Stopped. It cannot be Running when Selective Execution attempts to use its outputs. When using Selective Execution, you can choose any number of steps to run, as long as they form a contiguous portion of the pipeline.
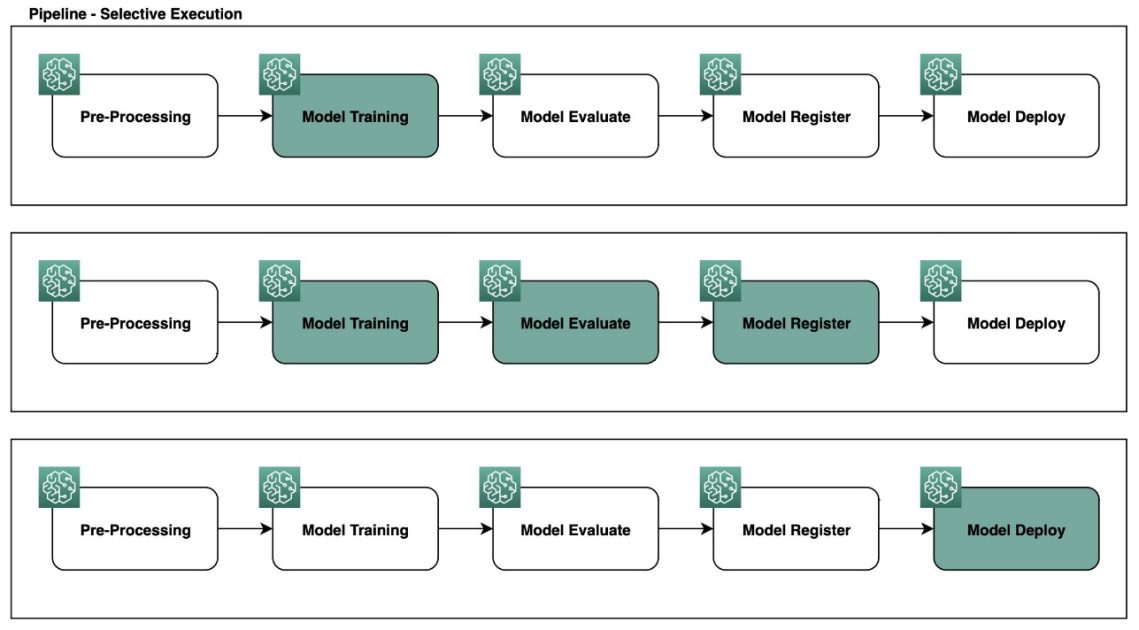
The following diagram illustrates the pipeline behavior with a full run.
The following diagram illustrates the pipeline behavior using Selective Execution.

In the following sections, we show how to use Selective Execution for various scenarios, including complex workflows in pipeline Direct Acyclic Graphs (DAGs).
Prerequisites
To start experimenting with Selective Execution, we need to first set up the following components of your SageMaker environment:
- SageMaker Python SDK – Ensure that you have an updated SageMaker Python SDK installed in your Python environment. You can run the following command from your notebook or terminal to install or upgrade the SageMaker Python SDK version to 2.162.0 or higher:
python3 -m pip install sagemaker>=2.162.0orpip3 install sagemaker>=2.162.0. - Access to SageMaker Studio (optional) – Amazon SageMaker Studio can be helpful for visualizing pipeline runs and interacting with preexisting pipeline ARNs visually. If you don’t have access to SageMaker Studio or are using on-demand notebooks or other IDEs, you can still follow this post and interact with your pipeline ARNs using the Python SDK.
The sample code for a full end-to-end walkthrough is available in the GitHub repo.
Setup
With the sagemaker>=1.162.0 Python SDK, we introduced the SelectiveExecutionConfig class as part of the sagemaker.workflow.selective_execution_config module. The Selective Execution feature relies on a pipeline ARN that has been previously marked as Succeeded, Failed or Stopped. The following code snippet demonstrates how to import the SelectiveExecutionConfig class, retrieve the reference pipeline ARN, and gather associated pipeline steps and runtime parameters governing the pipeline run:
import boto3
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.selective_execution_config import SelectiveExecutionConfig
sm_client = boto3.client('sagemaker')
# reference the name of your sample pipeline
pipeline_name = "AbalonePipeline"
# filter for previous success pipeline execution arns
pipeline_executions = [_exec
for _exec in Pipeline(name=pipeline_name).list_executions()['PipelineExecutionSummaries']
if _exec['PipelineExecutionStatus'] == "Succeeded"
]
# get the last successful execution
latest_pipeline_arn = pipeline_executions[0]['PipelineExecutionArn']
print(latest_pipeline_arn)
>>> arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/x62pbar3gs6h
# list all steps of your sample pipeline
execution_steps = sm_client.list_pipeline_execution_steps(
PipelineExecutionArn=latest_pipeline_arn
)['PipelineExecutionSteps']
print(execution_steps)
>>>
[{'StepName': 'Abalone-Preprocess',
'StartTime': datetime.datetime(2023, 6, 27, 4, 41, 30, 519000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 41, 30, 986000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'ProcessingJob': {'Arn': 'arn:aws:sagemaker:us-east-1:123123123123:processing-job/pipelines-fvsmu7m7ki3q-Abalone-Preprocess-d68CecvHLU'}},
'SelectiveExecutionResult': {'SourcePipelineExecutionArn': 'arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/ksm2mjwut6oz'}},
{'StepName': 'Abalone-Train',
'StartTime': datetime.datetime(2023, 6, 27, 4, 41, 31, 320000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 43, 58, 224000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'TrainingJob': {'Arn': 'arn:aws:sagemaker:us-east-1:123123123123:training-job/pipelines-x62pbar3gs6h-Abalone-Train-PKhAc1Q6lx'}}},
{'StepName': 'Abalone-Evaluate',
'StartTime': datetime.datetime(2023, 6, 27, 4, 43, 59, 40000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 57, 43, 76000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'ProcessingJob': {'Arn': 'arn:aws:sagemaker:us-east-1:123123123123:processing-job/pipelines-x62pbar3gs6h-Abalone-Evaluate-vmkZDKDwhk'}}},
{'StepName': 'Abalone-MSECheck',
'StartTime': datetime.datetime(2023, 6, 27, 4, 57, 43, 821000, tzinfo=tzlocal()),
'EndTime': datetime.datetime(2023, 6, 27, 4, 57, 44, 124000, tzinfo=tzlocal()),
'StepStatus': 'Succeeded',
'AttemptCount': 0,
'Metadata': {'Condition': {'Outcome': 'True'}}}]
# list all configureable pipeline parameters
# params can be altered during selective execution
parameters = sm_client.list_pipeline_parameters_for_execution(
PipelineExecutionArn=latest_pipeline_arn
)['PipelineParameters']
print(parameters)
>>>
[{'Name': 'XGBNumRounds', 'Value': '120'},
{'Name': 'XGBSubSample', 'Value': '0.9'},
{'Name': 'XGBGamma', 'Value': '2'},
{'Name': 'TrainingInstanceCount', 'Value': '1'},
{'Name': 'XGBMinChildWeight', 'Value': '4'},
{'Name': 'XGBETA', 'Value': '0.25'},
{'Name': 'ApprovalStatus', 'Value': 'PendingManualApproval'},
{'Name': 'ProcessingInstanceCount', 'Value': '1'},
{'Name': 'ProcessingInstanceType', 'Value': 'ml.t3.medium'},
{'Name': 'MseThreshold', 'Value': '6'},
{'Name': 'ModelPath',
'Value': 's3://sagemaker-us-east-1-123123123123/Abalone/models/'},
{'Name': 'XGBMaxDepth', 'Value': '12'},
{'Name': 'TrainingInstanceType', 'Value': 'ml.c5.xlarge'},
{'Name': 'InputData',
'Value': 's3://sagemaker-us-east-1-123123123123/sample-dataset/abalone/abalone.csv'}]Use cases
In this section, we present a few scenarios where Selective Execution can potentially save time and resources. We use a typical pipeline flow, which includes steps such as data extraction, training, evaluation, model registration and deployment, as a reference to demonstrate the advantages of Selective Execution.
SageMaker Pipelines allows you to define runtime parameters for your pipeline run using pipeline parameters. When a new run is triggered, it typically runs the entire pipeline from start to finish. However, if step caching is enabled, SageMaker Pipelines will attempt to find a previous run of the current pipeline step with the same attribute values. If a match is found, SageMaker Pipelines will use the outputs from the previous run instead of recomputing the step. Note that even with step caching enabled, SageMaker Pipelines will still run the entire workflow to the end by default.
With the release of the Selective Execution feature, you can now rerun an entire pipeline workflow or selectively run a subset of steps using a prior pipeline ARN. This can be done even without step caching enabled. The following use cases illustrate the various ways you can use Selective Execution.
Use case 1: Run a single step
Data scientists often focus on the training stage of a MLOps pipeline and don’t want to worry about the preprocessing or deployment steps. Selective Execution allows data scientists to focus on just the training step and modify training parameters or hyperparameters on the fly to improve the model. This can save time and reduce cost because compute resources are only utilized for running user-selected pipeline steps. See the following code:
# select a reference pipeline arn and subset step to execute
selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/9e3ljoql7s0n",
selected_steps=["Abalone-Train"]
)
# start execution of pipeline subset
select_execution = pipeline.start(
selective_execution_config=selective_execution_config,
parameters={
"XGBNumRounds": 120,
"XGBSubSample": 0.9,
"XGBGamma": 2,
"XGBMinChildWeight": 4,
"XGBETA": 0.25,
"XGBMaxDepth": 12
}
)The following figures illustrate the pipeline with one step in process and then complete.


Use case 2: Run multiple contiguous pipeline steps
Continuing with the previous use case, a data scientist wants to train a new model and evaluate its performance against a golden test dataset. This evaluation is crucial to ensure that the model meets rigorous guidelines for user acceptance testing (UAT) or production deployment. However, the data scientist doesn’t want to run the entire pipeline workflow or deploy the model. They can use Selective Execution to focus solely on the training and evaluation steps, saving time and resources while still getting the validation results they need:
# select a reference pipeline arn and subset step to execute
selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/9e3ljoql7s0n",
selected_steps=["Abalone-Train", "Abalone-Evaluate"]
)
# start execution of pipeline subset
select_execution = pipeline.start(
selective_execution_config=selective_execution_config,
parameters={
"ProcessingInstanceType": "ml.t3.medium",
"XGBNumRounds": 120,
"XGBSubSample": 0.9,
"XGBGamma": 2,
"XGBMinChildWeight": 4,
"XGBETA": 0.25,
"XGBMaxDepth": 12
}
)Use case 3: Update and rerun failed pipeline steps
You can use Selective Execution to rerun failed steps within a pipeline or resume the run of a pipeline from a failed step onwards. This can be useful for troubleshooting and debugging failed steps because it allows developers to focus on the specific issues that need to be addressed. This can lead to more efficient problem-solving and faster iteration times. The following example illustrates how you can choose to rerun just the failed step of a pipeline.

# select a previously failed pipeline arn
selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/fvsmu7m7ki3q",
selected_steps=["Abalone-Evaluate"]
)
# start execution of failed pipeline subset
select_execution = pipeline.start(
selective_execution_config=selective_execution_config
)
Alternatively, a data scientist can resume a pipeline from a failed step to the end of the workflow by specifying the failed step and all the steps that follow it in the SelectiveExecutionConfig.
Use case 4: Pipeline coverage
In some pipelines, certain branches are less frequently run than others. For example, there might be a branch that only runs when a specific condition fails. It’s important to test these branches thoroughly to ensure that they work as expected when a failure does occur. By testing these less frequently run branches, developers can verify that their pipeline is robust and that error-handling mechanisms effectively maintain the desired workflow and produce reliable results.

selective_execution_config = SelectiveExecutionConfig(
source_pipeline_execution_arn="arn:aws:sagemaker:us-east-1:123123123123:pipeline/AbalonePipeline/execution/9e3ljoql7s0n",
selected_steps=["Abalone-Train", "Abalone-Evaluate", "Abalone-MSECheck", "Abalone-FailNotify"]
)
Conclusion
In this post, we discussed the Selective Execution feature of SageMaker Pipelines, which empowers you to selectively run specific steps of your ML workflows. This capability leads to significant time and computational resource savings. We provided some sample code in the GitHub repo that demonstrates how to use Selective Execution and presented various scenarios where it can be advantageous for users. If you would like to learn more about Selective Execution, refer to our Developer Guide and API Reference Guide.
To explore the available steps within the SageMaker Pipelines workflow in more detail, refer to Amazon SageMaker Model Building Pipeline and SageMaker Workflows. Additionally, you can find more examples showcasing different use cases and implementation approaches using SageMaker Pipelines in the AWS SageMaker Examples GitHub repository. These resources can further enhance your understanding and help you take advantage of the full potential of SageMaker Pipelines and Selective Execution in your current and future ML projects.
About the Authors
 Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
Pranav Murthy is an AI/ML Specialist Solutions Architect at AWS. He focuses on helping customers build, train, deploy and migrate machine learning (ML) workloads to SageMaker. He previously worked in the semiconductor industry developing large computer vision (CV) and natural language processing (NLP) models to improve semiconductor processes. In his free time, he enjoys playing chess and traveling.
 Akhil Numarsu is a Sr.Product Manager-Technical focused on helping teams accelerate ML outcomes through efficient tools and services in the cloud. He enjoys playing Table Tennis and is a sports fan.
Akhil Numarsu is a Sr.Product Manager-Technical focused on helping teams accelerate ML outcomes through efficient tools and services in the cloud. He enjoys playing Table Tennis and is a sports fan.
 Nishant Krishnamoorthy is a Sr. Software Development Engineer with Amazon Stores. He holds a masters degree in Computer Science and currently focuses on accelerating ML Adoption in different orgs within Amazon by building and operationalizing ML solutions on SageMaker.
Nishant Krishnamoorthy is a Sr. Software Development Engineer with Amazon Stores. He holds a masters degree in Computer Science and currently focuses on accelerating ML Adoption in different orgs within Amazon by building and operationalizing ML solutions on SageMaker.


