This guest post is written by Vihan Lakshman, Tharun Medini, and Anshumali Shrivastava from ThirdAI.
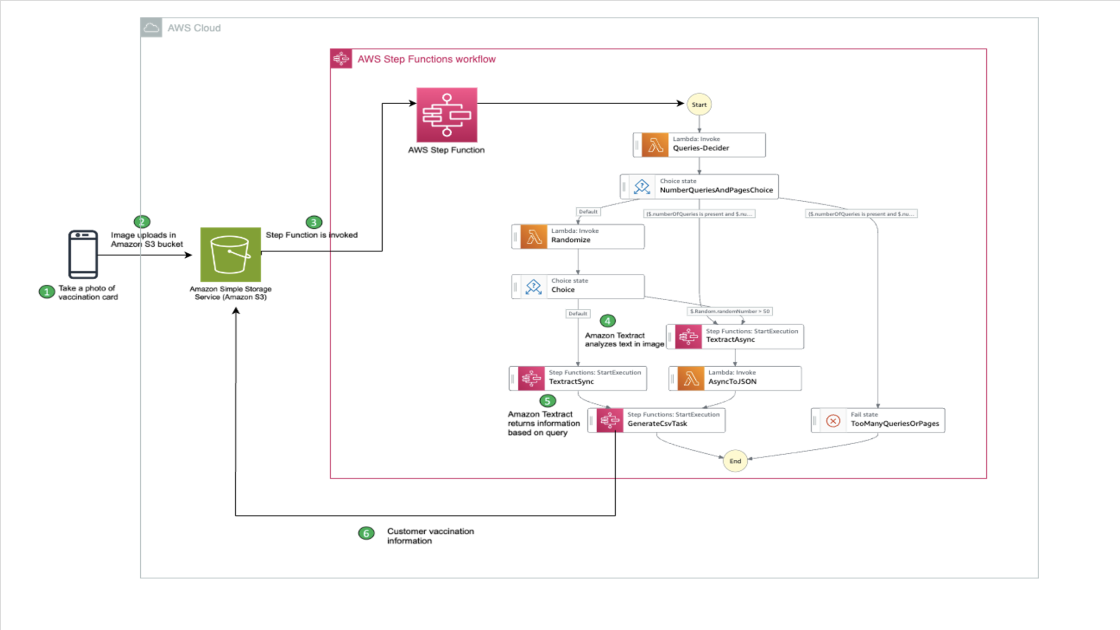
Large-scale deep learning has recently produced revolutionary advances in a vast array of fields. Although this stunning progress in artificial intelligence remains remarkable, the financial costs and energy consumption required to train these models has emerged as a critical bottleneck due to the need for specialized hardware like GPUs. Traditionally, even modestly sized neural models have required costly hardware accelerators for training, which limits the number of organizations with the financial means to take full advantage of this technology.
Founded in 2021, ThirdAI Corp. is a startup dedicated to the mission of democratizing artificial intelligence technologies through algorithmic and software innovations that fundamentally change the economics of deep learning. We have developed a sparse deep learning engine, known as BOLT, that is specifically designed for training and deploying models on standard CPU hardware as opposed to costly and energy-intensive accelerators like GPUs. Many of our customers have reported strong satisfaction with ThirdAI’s ability to train and deploy deep learning models for critical business problems on cost-effective CPU infrastructure.
In this post, we investigate of potential for the AWS Graviton3 processor to accelerate neural network training for ThirdAI’s unique CPU-based deep learning engine.
The benefits of high-performance CPUs
At ThirdAI, we achieve these breakthroughs in efficient neural network training on CPUs through proprietary dynamic sparse algorithms that activate only a subset of neurons for a given input (see the following figure), thereby side-stepping the need for full dense computations. Unlike other approaches to sparse neural network training, ThirdAI uses locality-sensitive hashing to dynamically select neurons for a given input as shown in the bold lines below. In certain cases, we have even observed that our sparse CPU-based models train faster than the comparable dense architecture on GPUs.
Given that many of our target customers operate in the cloud—and among those, the majority use AWS—we were excited to try out the AWS Graviton3 processor to see if the impressive price-performance improvements of Amazon’s silicon innovation would translate to our unique workload of sparse neural network training and thereby provide further savings for customers. Although both the research community and the AWS Graviton team have delivered exciting advances in accelerating neural network inference on CPU instances, we at ThirdAI are, to our knowledge, the first to seriously study how to train neural models on CPUs efficiently.
As shown in our results, we observed a significant training speedup with AWS Graviton3 over the comparable Intel and NVIDIA instances on several representative modeling workloads.
Instance types
For our evaluation, we considered two comparable AWS CPU instances: a c6i.8xlarge machine powered by Intel’s Ice Lake processor and a c7g.8xlarge powered by AWS Graviton3. The following table summarizes the details of each instance.
| Instance | vCPU | RAM (GB) | Processor | On-Demand Price (us-east-1) |
| c7g.8xlarge | 32 | 64 | AWS Graviton3 | $1.1562/hr |
| c6i.8xlarge | 32 | 64 | Intel Ice Lake | $1.36/hr |
| g5g.8xlarge (GPU) | 32 | 64 with 16 GB GPU Memory | AWS Graviton2 processors with 1 NVIDIA T4G GPU | $1.3720/hr |
Evaluation 1: Extreme classification
For our first evaluation, we focus on the problem of extreme multi-label classification (XMC), an increasingly popular machine learning (ML) paradigm with a number of practical applications in search and recommendations (including at Amazon). For our evaluation, we focus on the public Amazon-670K product recommendation task, which, given an input product, identifies similar products from a collection of over 670,000 items.
In this experiment, we benchmark ThirdAI’s BOLT engine against TensorFlow 2.11 and PyTorch 2.0 on the aforementioned hardware choices: Intel Ice Lake, AWS Graviton3, and an NVIDIA T4G GPU. For our experiments on Intel and AWS Graviton, we use the AWS Deep Learning AMI (Ubuntu 18.04) version 59.0. For our GPU evaluation, we use the NVIDIA GPU-Optimized Arm64 AMI, available via the AWS Marketplace. For this evaluation, we use the SLIDE model architecture, which achieves both competitive performance on this extreme classification task and strong training performance on CPUs. For our TensorFlow and PyTorch comparisons, we implement the analogous version of the SLIDE multi-layer perceptron (MLP) architecture with dense matrix multiplications. We train each model for five epochs (full passes through the training dataset) with a fixed batch size of 256 and learning rate of 0.001. We observed that all models achieved the same test accuracy of 33.6%.
The following chart compares the training time of ThirdAI’s BOLT to TensorFlow 2.11 and PyTorch 2.0 on the Amazon670k extreme classification benchmark. All models achieve the same test precision. We observe that AWS Graviton3 considerably accelerates the performance of BOLT out of the box with no customizations needed—by approximately 40%. ThirdAI’s BOLT on AWS Graviton3 also achieves considerably faster training than the TensorFlow or PyTorch models trained on the GPU. Note that there is no ThirdAI result on the NVIDIA GPU benchmark because BOLT is designed to run on CPUs. We do not include TensorFlow and PyTorch CPU benchmarks because of the prohibitively long training time.

The following table summarizes the training time and test accuracy for each processor/specialized processor(GPU).
| Processor | Engine | Training Time (s) | Test Accuracy |
| Intel Ice Lake (c6i.8xlarge) | BOLT | 1470 | 33.6 |
| AWS Graviton3 (c7g.8xlarge) | BOLT | 935 | 33.6 |
| NVIDIA T4G (g5g.8xlarge) | TensorFlow | 7550 | 33.6 |
| NVIDIA T4G (g5g.8xlarge) | PyTorch | 5130 | 33.6 |
Evaluation 2: Yelp Polarity sentiment analysis
For our second evaluation, we focus on the popular Yelp Polarity sentiment analysis benchmark, which involves classifying a review as positive or negative. For this evaluation, we compare ThirdAI’s Universal Deep Transformers (UDT) model against a fine-tuned DistilBERT network, a compressed pre-trained language model that achieves near-state-of-the-art performance with reduced inference latency. Because fine-tuning DistilBERT models on a CPU would take a prohibitively long time (at least several days), we benchmark ThirdAI’s CPU-based models against DistilBERT fine-tuned on a GPU. We train all models with a batch size of 256 for a single pass through the data (one epoch). We note that we can achieve slightly higher accuracy with BOLT with additional passes through the data, but we restrict ourselves to a single pass in this evaluation for consistency.
As shown in the following figure, AWS Graviton3 again accelerates ThirdAI’s UDT model training considerably. Furthermore, UDT is able to achieve comparable test accuracy to DistilBERT with a fraction of the training time and without the need for a GPU. We note that there has also been recent work in optimizing the fine-tuning of Yelp Polarity on CPUs. Our models, however, still achieve greater efficiency gains and avoid the cost of pre-training, which is substantial and requires the use of hardware accelerators like GPUs.

The following table summarizes the training time, test accuracy, and inference latency.
| Processor | Engine | Model | Training Time (s) | Test Accuracy | Inference Latency (ms) |
| Intel Icelake (c6i.8xlarge) | BOLT | UDT | 47 | 93.2 | <1 |
| Graviton3 (c7g.8xlarge) | BOLT | UDT | 29 | 92.9 | <1 |
| T4G GPU (g5g.8xlarge) | TensorFlow | DistilBERT | 4200 | 93.3 | 8.7 |
| T4G GPU (g5g.8xlarge) | PyTorch | DistilBERT | 3780 | 93.4 | 8.3 |
Evaluation 3: Multi-class text classification (DBPedia)
For our final evaluation, we focus on the problem of multi-class text classification, which involves assigning a label to a given input text from a set of more than two output classes. We focus on the DBPedia benchmark, which consists of 14 possible output classes. Again, we see that AWS Graviton3 accelerates UDT performance over the comparable Intel instance by roughly 40%. We also see that BOLT achieves comparable results to the DistilBERT transformer-based model fine-tuned on a GPU while achieving sub-millisecond latency.

The following table summarizes the training time, test accuracy, and inference latency.
| Processor | Engine | Model | Training Time (s) | Test Accuracy | Inference Latency (ms) |
| Intel Icelake (c6i.8xlarge) | BOLT | UDT | 23 | 98.23 | <1 |
| Graviton3 (c7g.8xlarge) | BOLT | UDT | 14 | 98.10 | <1 |
| T4G GPU (g5g.8xlarge) | TensorFlow | DistilBERT | 4320 | 99.23 | 8.6 |
| T4G GPU (g5g.8xlarge) | PyTorch | DistilBERT | 3480 | 99.29 | 8 |
Get started with ThirdAI on AWS Graviton
We have designed our BOLT software for compatibility with all major CPU architectures, including AWS Graviton3. In fact, we didn’t have to make any customizations to our code to run on AWS Graviton3. Therefore, you can use ThirdAI for model training and deployment on AWS Graviton3 with no additional effort. In addition, as detailed in our recent research whitepaper, we have developed a set of novel mathematical techniques to automatically tune the specialized hyperparameters associated with our sparse models, allowing our models to work well immediately out of the box.
We also note that our models primarily work well for search, recommendation, and natural language processing tasks that typically feature large, high-dimensional output spaces and a requirement of extremely low inference latency. We are actively working on extending our methods to additional domains, such as computer vision, but be aware that our efficiency improvements do not translate to all ML domains at this time.
Conclusion
In this post, we investigated the potential for the AWS Graviton3 processor to accelerate neural network training for ThirdAI’s unique CPU-based deep learning engine. Our benchmarks on search, text classification, and recommendations benchmarks suggest that AWS Graviton3 can accelerate ThirdAI’s model training workloads by 30–40% over the comparable x86 instances with a price-performance improvement of nearly 50%. Furthermore, because AWS Graviton3 instances are available at a lower cost than the analogous Intel and NVIDIA machines and enable shorter training and inference times, you can further unlock the value of the AWS pay-as-you-go usage model by using lower-cost machines for shorter durations of time.
We are very excited by the price and performance savings of AWS Graviton3 and will look to pass on these improvements to our customers so they can enjoy faster ML training and inference with improved performance on low-cost CPUs. As customers of AWS ourselves, we are delighted by the speed at which AWS Graviton3 allows us to experiment with our models, and we look forward to using more cutting-edge silicon innovation from AWS going forward. Graviton Technical Guide is a good resource to consider while evaluating your ML workloads to run on Graviton. You can also try Graviton t4g instances free trial.
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post. At the time of writing the blog the most current instance were c6i and hence the comparison was done with c6i instances.
About the Author
Vihan Lakshman – Vihan Lakshman is a research scientist at ThirdAI Corp. focused on developing systems for resource-efficient deep learning. Prior to ThirdAI, he worked as an Applied Scientist at Amazon and received undergraduate and master’s degrees from Stanford University. Vihan is also a recipient of a National Science Foundation research fellowship.
Tharun Medini – Tharun Medini is the co-founder and CTO of ThirdAI Corp. He did his PhD in “Hashing Algorithms for Search and Information Retrieval” at Rice University. Prior to ThirdAI, Tharun worked at Amazon and Target. Tharun is the recipient of numerous awards for his research, including the Ken Kennedy Institute BP Fellowship, the American Society of Indian Engineers Scholarship, and a Rice University Graduate Fellowship.
Anshumali Shrivastava – Anshumali Shrivastava is an associate professor in the computer science department at Rice University. He is also the Founder and CEO of ThirdAI Corp, a company that is democratizing AI to commodity hardware through software innovations. His broad research interests include probabilistic algorithms for resource-frugal deep learning. In 2018, Science news named him one of the Top-10 scientists under 40 to watch. He is a recipient of the National Science Foundation CAREER Award, a Young Investigator Award from the Air Force Office of Scientific Research, a machine learning research award from Amazon, and a Data Science Research Award from Adobe. He has won numerous paper awards, including Best Paper Awards at NIPS 2014 and MLSys 2022, as well as the Most Reproducible Paper Award at SIGMOD 2019. His work on efficient machine learning technologies on CPUs has been covered by popular press including Wall Street Journal, New York Times, TechCrunch, NDTV, etc.