This is a guest post co-written with Babu Srinivasan from MongoDB.
As industries evolve in today’s fast-paced business landscape, the inability to have real-time forecasts poses significant challenges for industries heavily reliant on accurate and timely insights. The absence of real-time forecasts in various industries presents pressing business challenges that can significantly impact decision-making and operational efficiency. Without real-time insights, businesses struggle to adapt to dynamic market conditions, accurately anticipate customer demand, optimize inventory levels, and make proactive strategic decisions. Industries such as Finance, Retail, Supply Chain Management, and Logistics face the risk of missed opportunities, increased costs, inefficient resource allocation, and the inability to meet customer expectations. By exploring these challenges, organizations can recognize the importance of real-time forecasting and explore innovative solutions to overcome these hurdles, enabling them to stay competitive, make informed decisions, and thrive in today’s fast-paced business environment.
By harnessing the transformative potential of MongoDB’s native time series data capabilities and integrating it with the power of Amazon SageMaker Canvas, organizations can overcome these challenges and unlock new levels of agility. MongoDB’s robust time series data management allows for the storage and retrieval of large volumes of time-series data in real-time, while advanced machine learning algorithms and predictive capabilities provide accurate and dynamic forecasting models with SageMaker Canvas.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution.
MongoDB Atlas
MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. It is a document based storage that provides a fully managed database, with built-in full-text and vector Search, support for Geospatial queries, Charts and native support for efficient time series storage and querying capabilities. MongoDB Atlas offers automatic sharding, horizontal scalability, and flexible indexing for high-volume data ingestion. Among all, the native time series capabilities is a standout feature, making it ideal for a managing high volume of time-series data, such as business critical application data, telemetry, server logs and more. With efficient querying, aggregation, and analytics, businesses can extract valuable insights from time-stamped data. By using these capabilities, businesses can efficiently store, manage, and analyze time-series data, enabling data-driven decisions and gaining a competitive edge.
Amazon SageMaker Canvas
Amazon SageMaker Canvas is a visual machine learning (ML) service that enables business analysts and data scientists to build and deploy custom ML models without requiring any ML experience or having to write a single line of code. SageMaker Canvas supports a number of use cases, including time-series forecasting, which empowers businesses to forecast future demand, sales, resource requirements, and other time-series data accurately. The service uses deep learning techniques to handle complex data patterns and enables businesses to generate accurate forecasts even with minimal historical data. By using Amazon SageMaker Canvas capabilities, businesses can make informed decisions, optimize inventory levels, improve operational efficiency, and enhance customer satisfaction.
The SageMaker Canvas UI lets you seamlessly integrate data sources from the cloud or on-premises, merge datasets effortlessly, train precise models, and make predictions with emerging data—all without coding. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs.
Solution overview
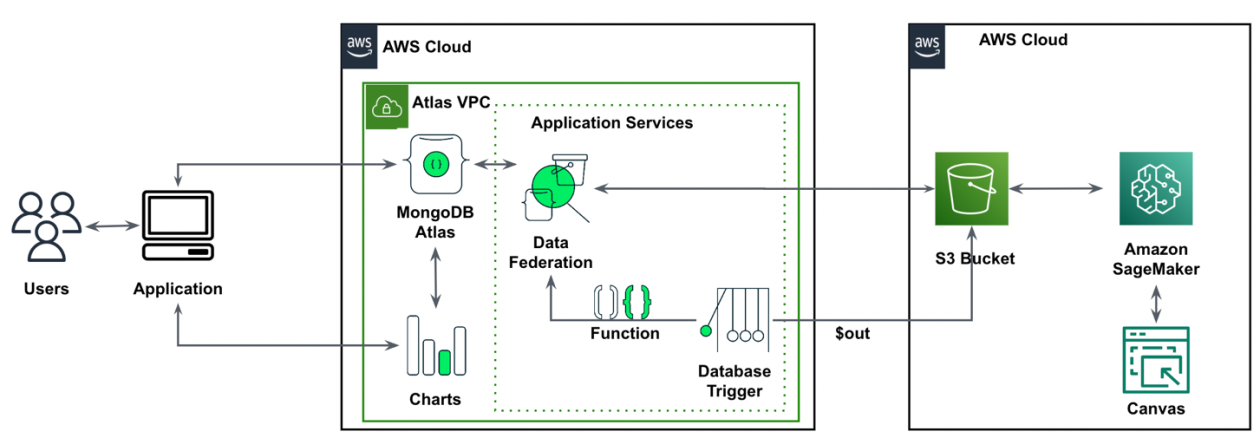
Users persist their transactional time series data in MongoDB Atlas. Through Atlas Data Federation, data is extracted into Amazon S3 bucket. Amazon SageMaker Canvas access the data to build models and create forecasts. The results of the forecasting are stored in an S3 bucket. Using the MongoDB Data Federation services, the forecasts are presented visually through MongoDB Charts.
The following diagram outlines the proposed solution architecture.
Prerequisites
For this solution we use MongoDB Atlas to store time series data, Amazon SageMaker Canvas to train a model and produce forecasts, and Amazon S3 to store data extracted from MongoDB Atlas.
Make sure you have the following prerequisites:
Configure MongoDB Atlas cluster
Create a free MongoDB Atlas cluster by following the instructions in Create a Cluster. Setup the Database access and Network access.
Populate a time series collection in MongoDB Atlas
For the purposes of this demonstration, you can use a sample data set from from Kaggle and upload the same to MongoDB Atlas with the MongoDB tools , preferably MongoDB Compass.
The following code shows a sample data set for a time series collection:
{
"store": "1 1",
"timestamp": { "2010-02-05T00:00:00.000Z"},
"temperature": "42.31",
"target_value": 2.572,
"IsHoliday": false
}The following screenshot shows the sample time series data in MongoDB Atlas:

Create an S3 Bucket
Create an S3 bucket in AWS , where the time series data need to be stored and analyzed. Note we have two folders. sales-train-data is used to store data extracted from MongoDB Atlas, while sales-forecast-output contains predictions from Canvas.

Create the Data Federation
Setup the Data Federation in Atlas and register the S3 bucket created previously as part of the data source. Notice the three different database/collections are created in the data federation for Atlas cluster, S3 bucket for MongoDB Atlas data and S3 bucket to store the Canvas results.
The following screenshots shows the setup of the data federation.

Setup the Atlas application service
Create the MongoDB Application Services to deploy the functions to transfer the data from MongoDB Atlas cluster to S3 bucket using the $out aggregation.

Verify the Datasource Configuration
The Application services create a new Altas Service Name that needs to be referred as the data services in the following function. Verify that the Atlas Service Name is created and note it for future reference.

Create the function
Setup the Atlas Application services to create the trigger and functions. The triggers need to be scheduled to write the data to S3 at a period frequency based on the business need for training the models.
The following script shows the function to write to the S3 bucket:
exports = function () {
const service = context.services.get("");
const db = service.db("")
const events = db.collection("");
const pipeline = [
{
"$out": {
"s3": {
"bucket": "<S3_bucket_name>",
"region": "<AWS_Region>",
"filename": {$concat: ["<S3path>/<filename>_",{"$toString": new Date(Date.now())}]},
"format": {
"name": "json",
"maxFileSize": "10GB"
}
}
}
}
];
return events.aggregate(pipeline);
};
Sample function
The function can be run through the Run tab and the errors can be debugged using the log features in the Application Services. In addition, the errors can be debugged using the Logs menu in the left pane.
The following screenshot shows the execution of the function along with the output:

Create dataset in Amazon SageMaker Canvas
The following steps assume that you have created a SageMaker domain and user profile. If you have not already done so, make sure that you configure the SageMaker domain and user profile. In the user profile, update your S3 bucket to be custom and supply your bucket name.

When complete, navigate to SageMaker Canvas, select your domain and profile, and select Canvas.

Create a dataset supplying the data source.

Select the dataset source as S3

Select the data location from the S3 bucket and select Create dataset.

Review the schema and click Create dataset

Upon successful import, the dataset will appear in the list as shown in the following screenshot.

Train the model
Next, we will use Canvas to set up to train the model. Select the dataset and click Create.

Create a model name, select Predictive analysis, and select Create.

Select target column

Next, click Configure time series model and select item_id as the Item ID column.

Select tm for the time stamp column

To specify the amount of time that you want to forecast, choose 8 weeks.

Now you are ready to preview the model or launch the build process.

After you preview the model or launch the build, your model will be created and can take up to four hours. You can leave the screen and return to see the model training status.

When the model is ready, select the model and click on the latest version

Review the model metrics and column impact and if you are satisfied with the model performance, click Predict.

Next, choose Batch prediction, and click Select dataset.

Select your dataset, and click Choose dataset.

Next, click Start Predictions.

Observe a job created or observe the job progress in SageMaker under Inference, Batch transform jobs.


When the job completes, select the job, and note the S3 path where Canvas stored the predictions.

Visualize forecast data in Atlas Charts
To visualize forecast data, create the MongoDB Atlas charts based on the Federated data (amazon-forecast-data) for P10, P50, and P90 forecasts as shown in the following chart.

Clean up
- Delete the MongoDB Atlas cluster
- Delete Atlas Data Federation Configuration
- Delete Atlas Application Service App
- Delete the S3 Bucket
- Delete Amazon SageMaker Canvas dataset and models
- Delete the Atlas Charts
- Log out of Amazon SageMaker Canvas
Conclusion
In this post we extracted time series data from MongoDB time series collection. This is a special collection optimized for storage and querying speed of time series data. We used Amazon SageMaker Canvas to train models and generate predictions and we visualized the predictions in Atlas Charts.
For more information, refer to the following resources.
About the authors
 Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
Igor Alekseev is a Senior Partner Solution Architect at AWS in Data and Analytics domain. In his role Igor is working with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect he implemented many projects in Big Data domain, including several data lakes in Hadoop ecosystem. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
 Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.
Babu Srinivasan is a Senior Partner Solutions Architect at MongoDB. In his current role, he is working with AWS to build the technical integrations and reference architectures for the AWS and MongoDB solutions. He has more than two decades of experience in Database and Cloud technologies . He is passionate about providing technical solutions to customers working with multiple Global System Integrators(GSIs) across multiple geographies.