Machine learning, particularly the training of large foundation models, relies heavily on the diversity and quality of data. These models, pre-trained on vast datasets, are the foundation of many modern AI applications, including language processing, image recognition, and more. The effectiveness of foundation models depends on how well they are trained, which is influenced by the data fed into them. Optimizing the selection and usage of data during the training process is an ongoing challenge, especially when computational resources are limited. The composition of pretraining data, distribution, and the ability to scale models without incurring significant overhead are crucial considerations in this field.
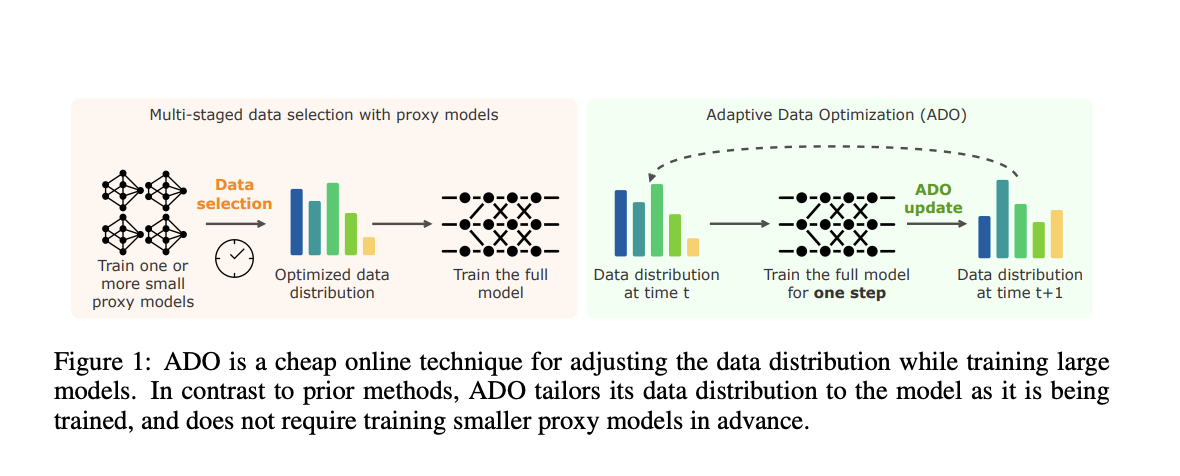
A major issue in training these models is allocating limited computational resources across different datasets or data domains. The primary challenge is that there are no clear guidelines on selecting and balancing data to maximize the model’s learning. Traditional approaches rely on smaller models to experiment with different data distributions or use dynamic data adjustment methods that depend on proxy models. Both approaches introduce significant overhead in terms of time and computational power. As the scale of models increases, these methods become less efficient and harder to generalize, leading to suboptimal performance in larger models. This inefficiency creates a significant bottleneck in the progress of training large-scale models.
Existing methods of handling data selection typically involve pre-training smaller proxy models to inform the main model’s training process. These proxy models estimate the optimal distribution of data across different domains. However, this approach comes with its drawbacks. First, it requires additional steps in the workflow, increasing the complexity of the training process. Second, these smaller models are not always reliable predictors of how a larger model will behave, which leads to increased costs and inefficiencies. For instance, training a proxy model for data selection may require 760 GPU hours on 8 Nvidia A100 GPUs, and often, several rounds of proxy training are necessary before applying the insights to larger models.
Researchers from Carnegie Mellon University, Stanford University, and Princeton University introduced Adaptive Data Optimization (ADO), a novel method that dynamically adjusts data distributions during training. ADO is an online algorithm that does not require smaller proxy models or additional external data. It uses scaling laws to assess the learning potential of each data domain in real time and adjusts the data mixture accordingly. This makes ADO significantly more scalable and easier to integrate into existing workflows without requiring complex modifications. The research team demonstrated that ADO can achieve comparable or even better performance than prior methods while maintaining computational efficiency.
The core of ADO lies in its ability to apply scaling laws to predict how much value a particular dataset or domain will bring to the model as training progresses. These scaling laws estimate the potential improvement in learning from each domain and allow ADO to adjust the data distribution on the fly. Instead of relying on static data policies, ADO refines the data mixture based on real-time feedback from the training model. The system tracks two main metrics: the domain’s learning potential, which shows how much the model can still gain from further optimization in a given domain, and a credit assignment score, which measures the domain’s contribution to reducing the training loss. This dynamic adjustment makes ADO a more efficient tool compared to traditional static data policies.
The performance of ADO was tested on various large-scale language models, including models with 124 million and 1.3 billion parameters. These experiments revealed that ADO could improve model performance across several benchmarks while adding only a minimal computational burden. For example, in one of the key experiments, ADO added less than 0.4% additional wall clock time to a 3.5-day training process of a 1.3-billion-parameter model. Regarding performance, ADO improved the model’s accuracy in zero-shot downstream tasks, surpassing baseline methods in six out of seven benchmarks at the 124 million scale and four out of seven benchmarks at the 1.3 billion scale. Notably, ADO achieved this performance without needing smaller proxy models or extensive modification to the training process, making it a more practical and cost-efficient solution for large-scale model training.

Key Takeaways from the Research on ADO:
- ADO eliminates the need for proxy models, simplifying the training process.
- Real-time adjustment of data distribution based on scaling laws ensures optimal model performance.
- ADO added only 0.4% to the training time of a 1.3-billion-parameter model.
- Achieved top performance in 6 out of 7 benchmarks for 124M models and 4 out of 7 for 1.3B models.
- Significantly reduces computational costs associated with data selection in large-scale model training.

In conclusion, ADO presents a significant breakthrough in optimizing data selection while training large models. ADO simplifies the training process while improving overall model performance by eliminating the need for proxy models and dynamically adjusting data distribution using real-time feedback. The method’s ability to scale efficiently across different model sizes, ranging from 124 million to 1.3 billion parameters, makes it highly adaptable. Also, ADO reduces the computational overhead typically associated with training large models, making it a practical solution for improving foundation models without additional costs. This research highlights the importance of intelligent data optimization in advancing machine learning efficiency.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.