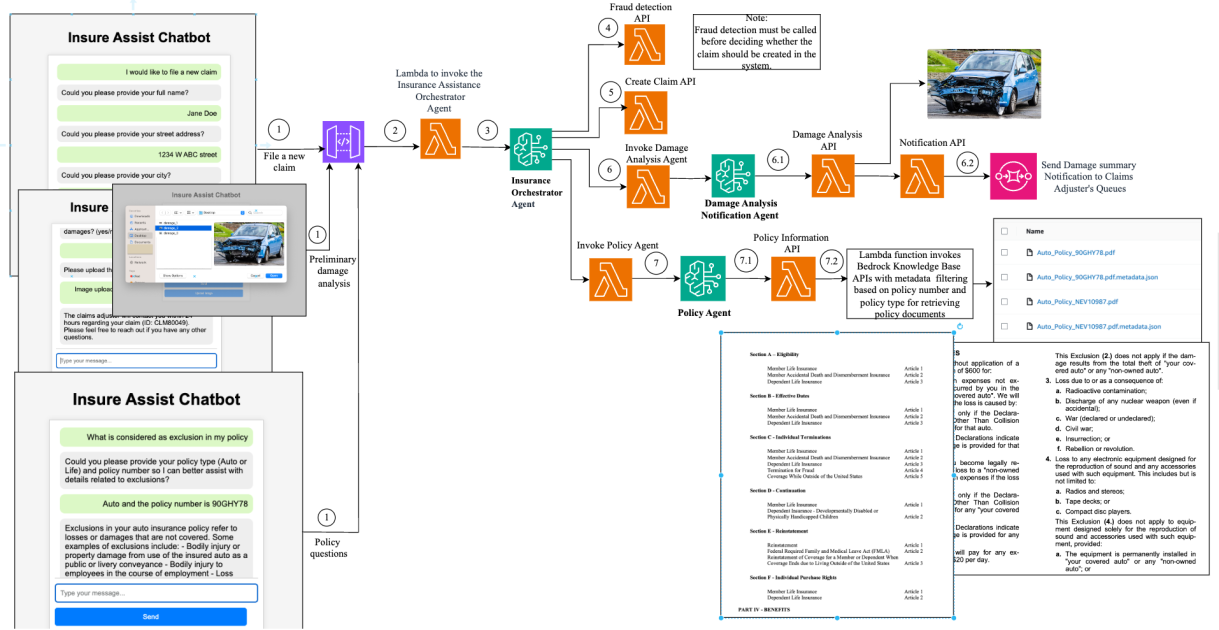
Retrieval Augmented Generation (RAG) is a state-of-the-art approach to building question answering systems that combines the strengths of retrieval and foundation models (FMs). RAG models first retrieve relevant information from a large corpus of text and then use a FM to synthesize an answer based on the retrieved information.
An end-to-end RAG solution involves several components, including a knowledge base, a retrieval system, and a generation system. Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models.
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and AWS CloudFormation, enabling organizations to quickly and effortlessly set up a powerful RAG system.
Solution overview
The solution provides an automated end-to-end deployment of a RAG workflow using Knowledge Bases for Amazon Bedrock. We use AWS CloudFormation to set up the necessary resources, including :
- An AWS Identity and Access Management (IAM) role
- An Amazon OpenSearch Serverless collection and index
- A knowledge base with its associated data source
The RAG workflow enables you to use your document data stored in an Amazon Simple Storage Service (Amazon S3) bucket and integrate it with the powerful natural language processing capabilities of FMs provided in Amazon Bedrock. The solution simplifies the setup process, allowing you to quickly deploy and start querying your data using the selected FM.
Prerequisites
To implement the solution provided in this post, you should have the following:
- An active AWS account and familiarity with FMs, Amazon Bedrock, and OpenSearch Serverless.
- An S3 bucket where your documents are stored in a supported format (.txt, .md, .html, .doc/docx, .csv, .xls/.xlsx, .pdf).
- The Amazon Titan Embeddings G1-Text model enabled in Amazon Bedrock. You can confirm it’s enabled on the Model access page of the Amazon Bedrock console. If the Amazon Titan Embeddings G1-Text model is enabled, the access status will show as Access granted, as shown in the following screenshot.
Set up the solution
When the prerequisite steps are complete, you’re ready to set up the solution:
- Clone the GitHub repository containing the solution files:
- Navigate to the solution directory:
- Run the sh script, which will create the deployment bucket, prepare the CloudFormation templates, and upload the ready CloudFormation templates and required artifacts to the deployment bucket:
While running deploy.sh, if you provide a bucket name as an argument to the script, it will create a deployment bucket with the specified name. Otherwise, it will use the default name format: e2e-rag-deployment-${ACCOUNT_ID}-${AWS_REGION}
As shown in the following screenshot, if you complete the preceding steps in an Amazon SageMaker notebook instance, you can run the bash deploy.sh at the terminal, which creates the deployment bucket in your account (account number has been redacted).

- After the script is complete, note the S3 URL of the main-template-out.yml.

- On the AWS CloudFormation console, create a new stack.
- For Template source, select Amazon S3 URL and enter the URL you copied earlier.
- Choose Next.

- Provide a stack name and specify the RAG workflow details according to your use case and then choose Next.


- Leave everything else as default and choose Next on the following pages.
- Review the stack details and select the acknowledgement check boxes.

- Choose Submit to start the deployment process.
You can monitor the stack deployment progress on the AWS CloudFormation console.

Test the solution
When the deployment is successful (which may take 7–10 minutes to complete), you can start testing the solution.
- On the Amazon Bedrock console, navigate to the created knowledge base.
- Choose Sync to initiate the data ingestion job.

- After data synchronization is complete, select the desired FM to use for retrieval and generation (it requires model access to be granted to this FM in Amazon Bedrock before using).

- Start querying your data using natural language queries.
That’s it! You can now interact with your documents using the RAG workflow powered by Amazon Bedrock.
Clean up
To avoid incurring future charges, delete the resources used in this solution:
- On the Amazon S3 console, manually delete the contents inside the bucket you created for template deployment, then delete the bucket.
- On the AWS CloudFormation console, choose Stacks in the navigation pane, select the main stack, and choose Delete.
Your created knowledge base will be deleted when you delete the stack.

Conclusion
In this post, we introduced an automated solution for deploying an end-to-end RAG workflow using Knowledge Bases for Amazon Bedrock and AWS CloudFormation. By using the power of AWS services and the preconfigured CloudFormation templates, you can quickly set up a powerful question answering system without the complexities of building and deploying individual components for RAG applications. This automated deployment approach not only saves time and effort, but also provides a consistent and reproducible setup, enabling you to focus on utilizing the RAG workflow to extract valuable insights from your data.
Try it out and see firsthand how it can streamline your RAG workflow deployment and enhance efficiency. Please share your feedback to us!
About the Authors
 Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
Sandeep Singh is a Senior Generative AI Data Scientist at Amazon Web Services, helping businesses innovate with generative AI. He specializes in generative AI, machine learning, and system design. He has successfully delivered state-of-the-art AI/ML-powered solutions to solve complex business problems for diverse industries, optimizing efficiency and scalability.
 Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. With a keen interest in exploring new frontiers in the field, she continuously strives to push boundaries. Outside of work, she loves traveling, working out, and exploring new things.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. With a keen interest in exploring new frontiers in the field, she continuously strives to push boundaries. Outside of work, she loves traveling, working out, and exploring new things.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.