
Introducing a framework to create AI agents that can understand human instructions and perform actions in open-ended settings
Human behaviour is remarkably complex. Even a simple request like, “Put the ball close to the box” still requires deep understanding of situated intent and language. The meaning of a word like ‘close’ can be difficult to pin down – placing the ball inside the box might technically be the closest, but it’s likely the speaker wants the ball placed next to the box. For a person to correctly act on the request, they must be able to understand and judge the situation and surrounding context.
Most artificial intelligence (AI) researchers now believe that writing computer code which can capture the nuances of situated interactions is impossible. Alternatively, modern machine learning (ML) researchers have focused on learning about these types of interactions from data. To explore these learning-based approaches and quickly build agents that can make sense of human instructions and safely perform actions in open-ended conditions, we created a research framework within a video game environment.
Today, we’re publishing a paper and collection of videos, showing our early steps in building video game AIs that can understand fuzzy human concepts – and therefore, can begin to interact with people on their own terms.
Much of the recent progress in training video game AI relies on optimising the score of a game. Powerful AI agents for StarCraft and Dota were trained using the clear-cut wins/losses calculated by computer code. Instead of optimising a game score, we ask people to invent tasks and judge progress themselves.
Using this approach, we developed a research paradigm that allows us to improve agent behaviour through grounded and open-ended interaction with humans. While still in its infancy, this paradigm creates agents that can listen, talk, ask questions, navigate, search and retrieve, manipulate objects, and perform many other activities in real-time.
This compilation shows behaviours of agents following tasks posed by human participants:
Learning in “the playhouse”
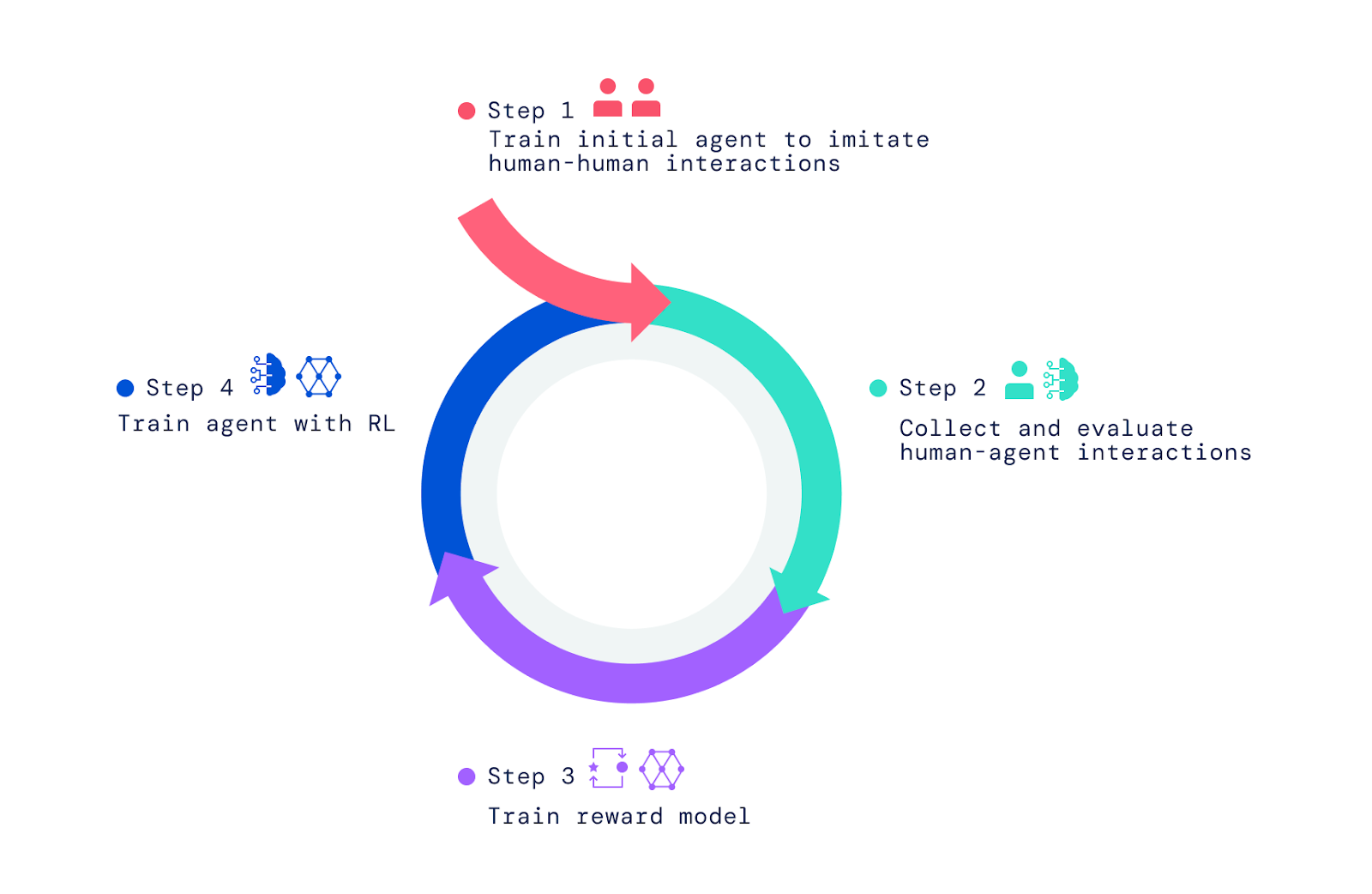
Our framework begins with people interacting with other people in the video game world. Using imitation learning, we imbued agents with a broad but unrefined set of behaviours. This “behaviour prior” is crucial for enabling interactions that can be judged by humans. Without this initial imitation phase, agents are entirely random and virtually impossible to interact with. Further human judgement of the agent’s behaviour and optimisation of these judgements by reinforcement learning (RL) produces better agents, which can then be improved again.
First we built a simple video game world based on the concept of a child’s “playhouse.” This environment provided a safe setting for humans and agents to interact and made it easy to rapidly collect large volumes of these interaction data. The house featured a variety of rooms, furniture, and objects configured in new arrangements for each interaction. We also created an interface for interaction.
Both the human and agent have an avatar in the game that enables them to move within – and manipulate – the environment. They can also chat with each other in real-time and collaborate on activities, such as carrying objects and handing them to each other, building a tower of blocks, or cleaning a room together. Human participants set the contexts for the interactions by navigating through the world, setting goals, and asking questions for agents. In total, the project collected more than 25 years of real-time interactions between agents and hundreds of (human) participants.
Observing behaviours that emerge
The agents we trained are capable of a huge range of tasks, some of which were not anticipated by the researchers who built them. For instance, we discovered that these agents can build rows of objects using two alternating colours or retrieve an object from a house that’s similar to another object the user is holding.
These surprises emerge because language permits a nearly endless set of tasks and questions via the composition of simple meanings. Also, as researchers, we do not specify the details of agent behaviour. Instead, the hundreds of humans who engage in interactions came up with tasks and questions during the course of these interactions.
Building the framework for creating these agents
To create our AI agents, we applied three steps. We started by training agents to imitate the basic elements of simple human interactions in which one person asks another to do something or to answer a question. We refer to this phase as creating a behavioural prior that enables agents to have meaningful interactions with a human with high frequency. Without this imitative phase, agents just move randomly and speak nonsense. They’re almost impossible to interact with in any reasonable fashion and giving them feedback is even more difficult. This phase was covered in two of our earlier papers, Imitating Interactive Intelligence, and Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning, which explored building imitation-based agents.
Moving beyond imitation learning
While imitation learning leads to interesting interactions, it treats each moment of interaction as equally important. To learn efficient, goal-directed behaviour, an agent needs to pursue an objective and master particular movements and decisions at key moments. For example, imitation-based agents don’t reliably take shortcuts or perform tasks with greater dexterity than an average human player.
Here we show an imitation-learning based agent and an RL-based agent following the same human instruction:
To endow our agents with a sense of purpose, surpassing what’s possible through imitation, we relied on RL, which uses trial and error combined with a measure of performance for iterative improvement. As our agents tried different actions, those that improved performance were reinforced, while those that decreased performance were penalised.
In games like Atari, Dota, Go, and StarCraft, the score provides a performance measure to be improved. Instead of using a score, we asked humans to assess situations and provide feedback, which helped our agents learn a model of reward.
Training the reward model and optimising agents
To train a reward model, we asked humans to judge if they observed events indicating conspicuous progress toward the current instructed goal or conspicuous errors or mistakes. We then drew a correspondence between these positive and negative events and positive and negative preferences. Since they take place across time, we call these judgements “inter-temporal.” We trained a neural network to predict these human preferences and obtained as a result a reward (or utility / scoring) model reflecting human feedback.
Once we trained the reward model using human preferences, we used it to optimise agents. We placed our agents into the simulator and directed them to answer questions and follow instructions. As they acted and spoke in the environment, our trained reward model scored their behaviour, and we used an RL algorithm to optimise agent performance.
So where do the task instructions and questions come from? We explored two approaches for this. First, we recycled the tasks and questions posed in our human dataset. Second, we trained agents to mimic how humans set tasks and pose questions, as shown in this video, where two agents, one trained to mimic humans setting tasks and posing questions (blue) and one trained to follow instructions and answer questions (yellow), interact with each other:
Evaluating and iterating to continue improving agents
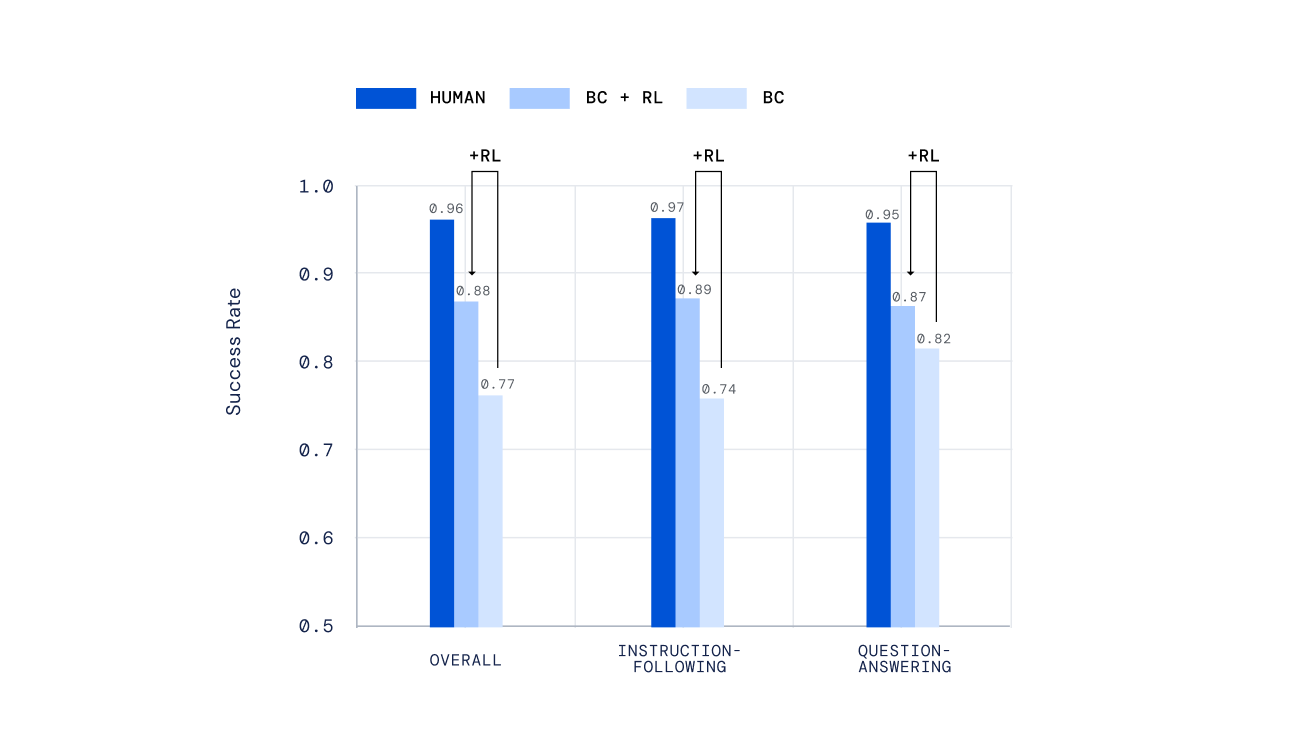
We used a variety of independent mechanisms to evaluate our agents, from hand-scripted tests to a new mechanism for offline human scoring of open-ended tasks created by people, developed in our previous work Evaluating Multimodal Interactive Agents. Importantly, we asked people to interact with our agents in real-time and judge their performance. Our agents trained by RL performed much better than those trained by imitation learning alone.
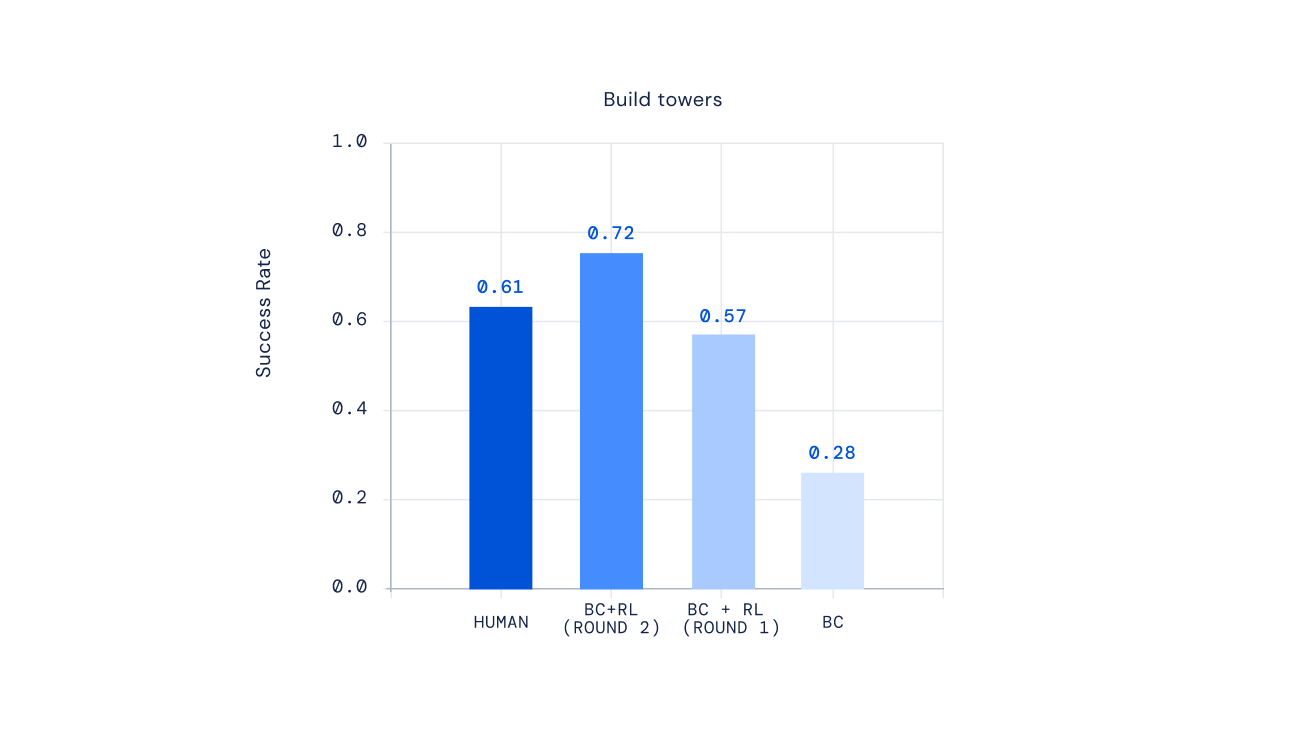
Finally, recent experiments show we can iterate the RL process to repeatedly improve agent behaviour. Once an agent is trained via RL, we asked people to interact with this new agent, annotate its behaviour, update our reward model, and then perform another iteration of RL. The result of this approach was increasingly competent agents. For some types of complex instructions, we could even create agents that outperformed human players on average.
The future of training AI for situated human preferences
The idea of training AI using human preferences as a reward has been around for a long time. In Deep reinforcement learning from human preferences, researchers pioneered recent approaches to aligning neural network based agents with human preferences. Recent work to develop turn-based dialogue agents explored similar ideas for training assistants with RL from human feedback. Our research has adapted and expanded these ideas to build flexible AIs that can master a broad scope of multi-modal, embodied, real-time interactions with people.
We hope our framework may someday lead to the creation of game AIs that are capable of responding to our naturally expressed meanings, rather than relying on hand-scripted behavioural plans. Our framework could also be useful for building digital and robotic assistants for people to interact with every day. We look forward to exploring the possibility of applying elements of this framework to create safe AI that’s truly helpful.
Excited to learn more? Check out our latest paper. Feedback and comments are welcome.

