OpenR: An Open-Source AI Framework Enhancing Reasoning in Large Language Models
Large language models (LLMs) have made significant progress in language generation, but their reasoning skills remain insufficient for complex problem-solving.…
Large language models (LLMs) have made significant progress in language generation, but their reasoning skills remain insufficient for complex problem-solving.…
Imagine having to straighten up a messy kitchen, starting with a counter littered with sauce packets. If your goal is…
In the rapidly evolving world of artificial intelligence, one pressing challenge that developers face is orchestrating complex multi-agent systems. These…
Have you ever wanted to travel through time to see what your future self might be like? Now, thanks to…
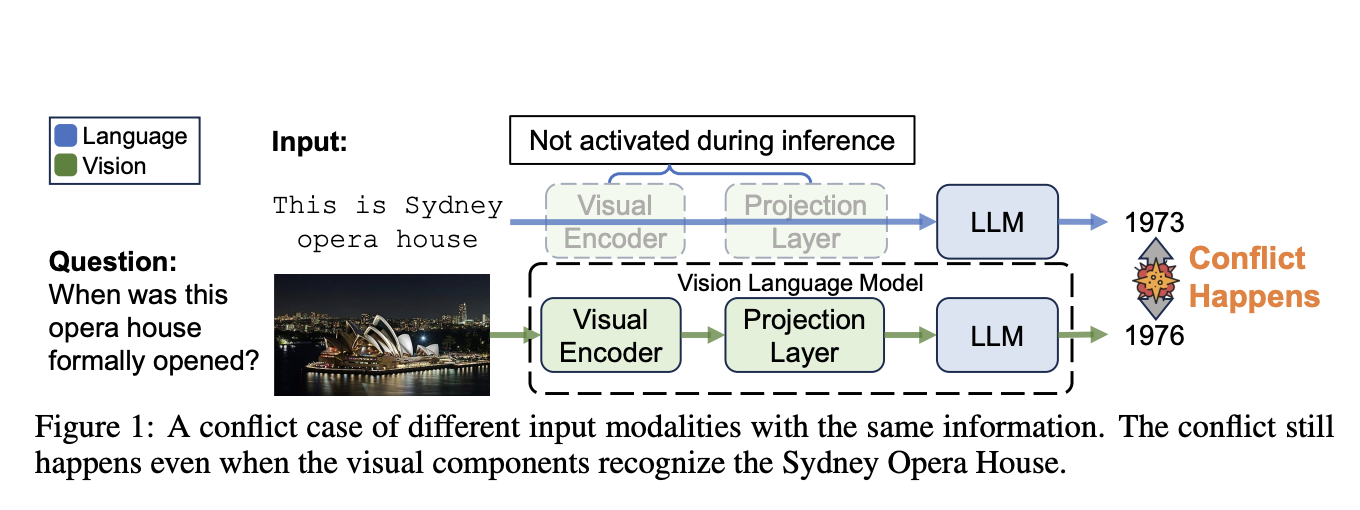
Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities for capturing and reasoning over multimodal inputs and can process both images…
A recent award from the U.S. Defense Advanced Research Projects Agency (DARPA) brings together researchers from Massachusetts Institute of Technology…
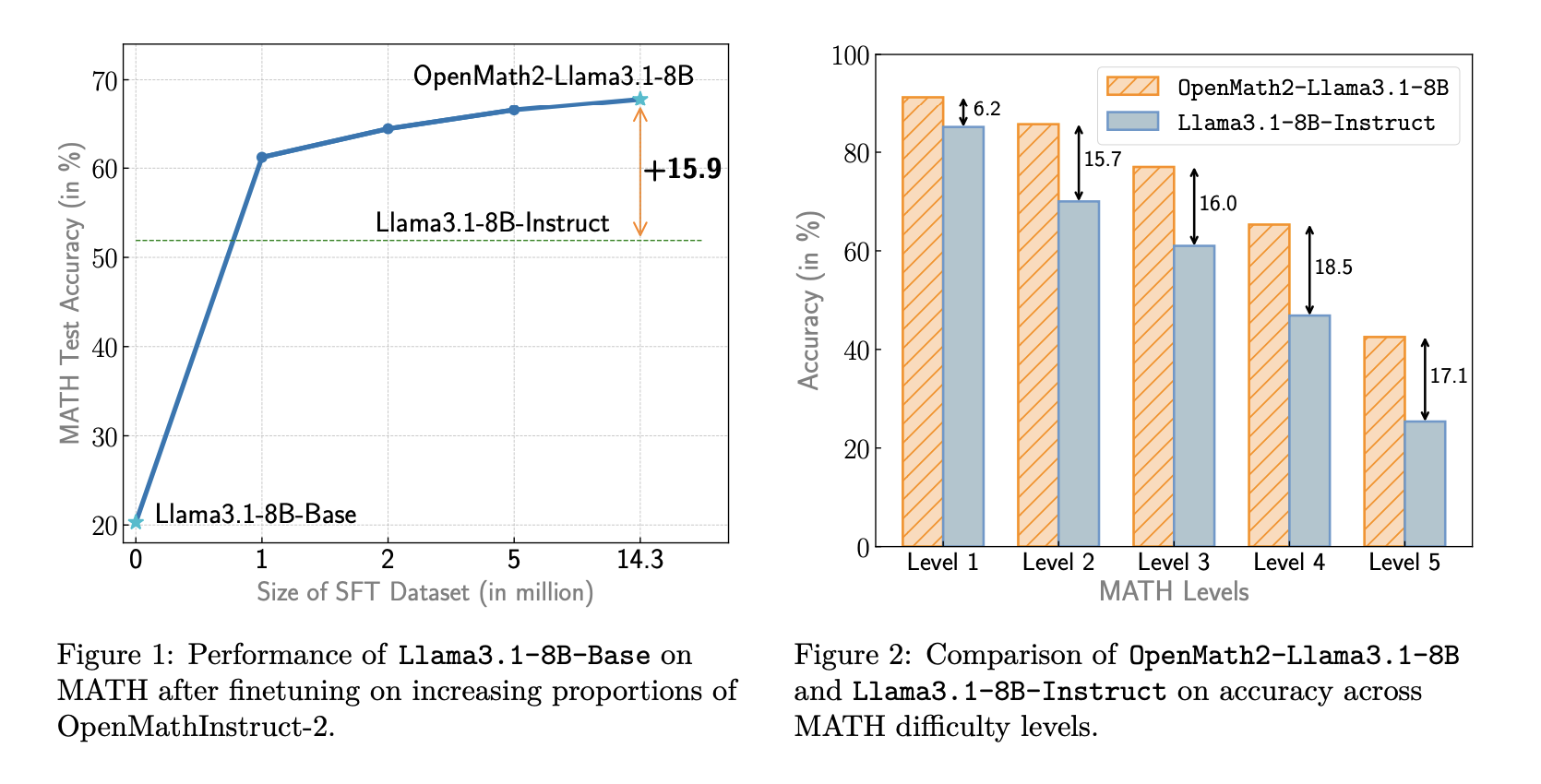
Language models have made significant strides in mathematical reasoning, with synthetic data playing a crucial role in their development. However,…
In the United States and around the world, democracy is under threat. Anti-democratic attitudes have become more prevalent, partisan polarization…
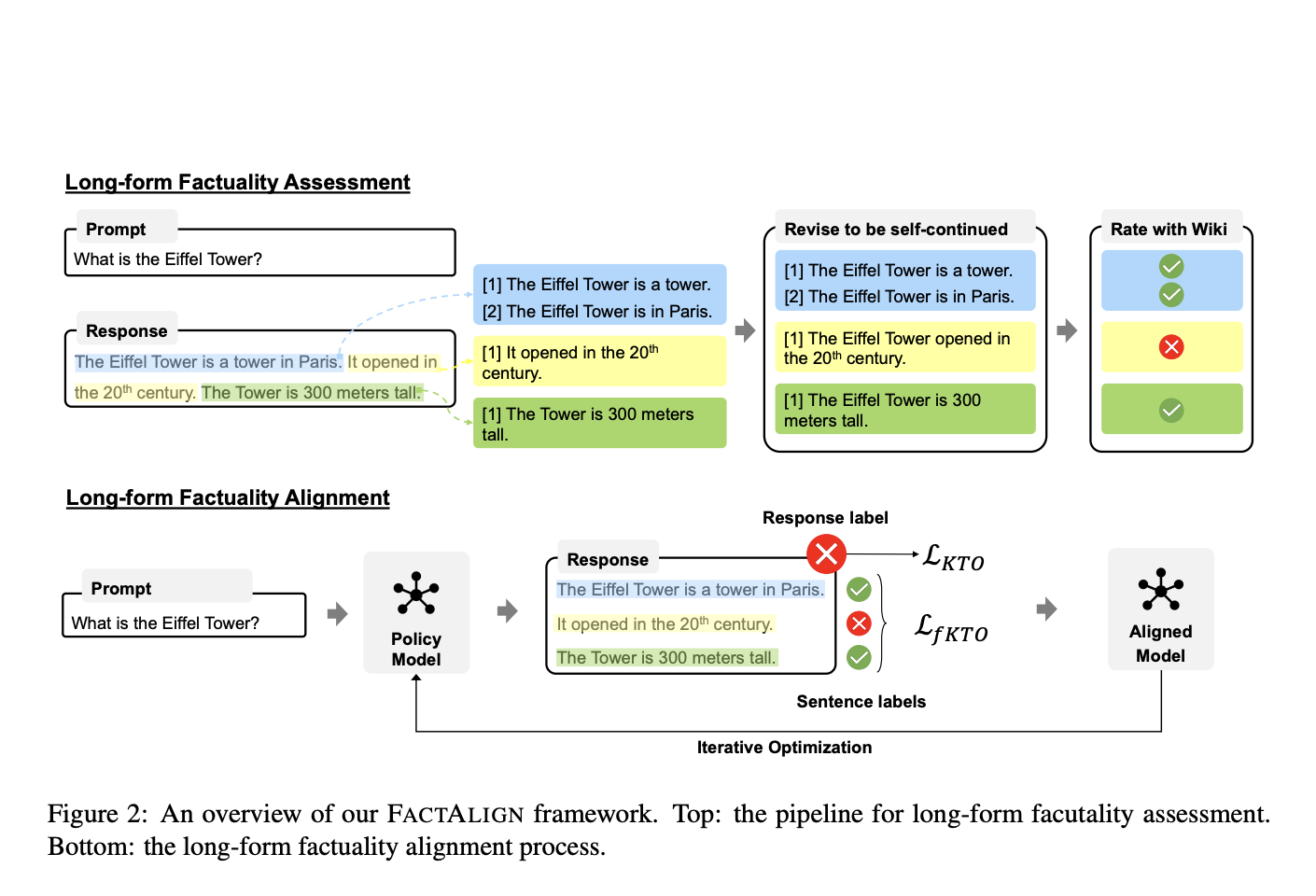
LLMs show great promise as advanced information access engines thanks to their ability to generate long-form, natural language responses. Their…
The German philosopher Fredrich Nietzsche once said that “invisible threads are the strongest ties.” One could think of “invisible threads”…