With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry.
Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface. You can perform all ML development steps and have complete access, control, and visibility into each step required to build, train, and deploy models.
Amazon Redshift is a fully managed, fast, secure, and scalable cloud data warehouse. Organizations often want to use SageMaker Studio to get predictions from data stored in a data warehouse such as Amazon Redshift.
As described in the AWS Well-Architected Framework, separating workloads across accounts enables your organization to set common guardrails while isolating environments. This can be particularly useful for certain security requirements, as well as to simplify cost controls and monitoring between projects and teams. Organizations with a multi-account architecture typically have Amazon Redshift and SageMaker Studio in two separate AWS accounts. Also, Amazon Redshift and SageMaker Studio are typically configured in VPCs with private subnets to improve security and reduce the risk of unauthorized access as a best practice.
Amazon Redshift natively supports cross-account data sharing when RA3 node types are used. If you’re using any other Amazon Redshift node types, such as DS2 or DC2, you can use VPC peering to establish a cross-account connection between Amazon Redshift and SageMaker Studio.
In this post, we walk through step-by-step instructions to establish a cross-account connection to any Amazon Redshift node type (RA3, DC2, DS2) by connecting the Amazon Redshift cluster located in one AWS account to SageMaker Studio in another AWS account in the same Region using VPC peering.
Solution overview
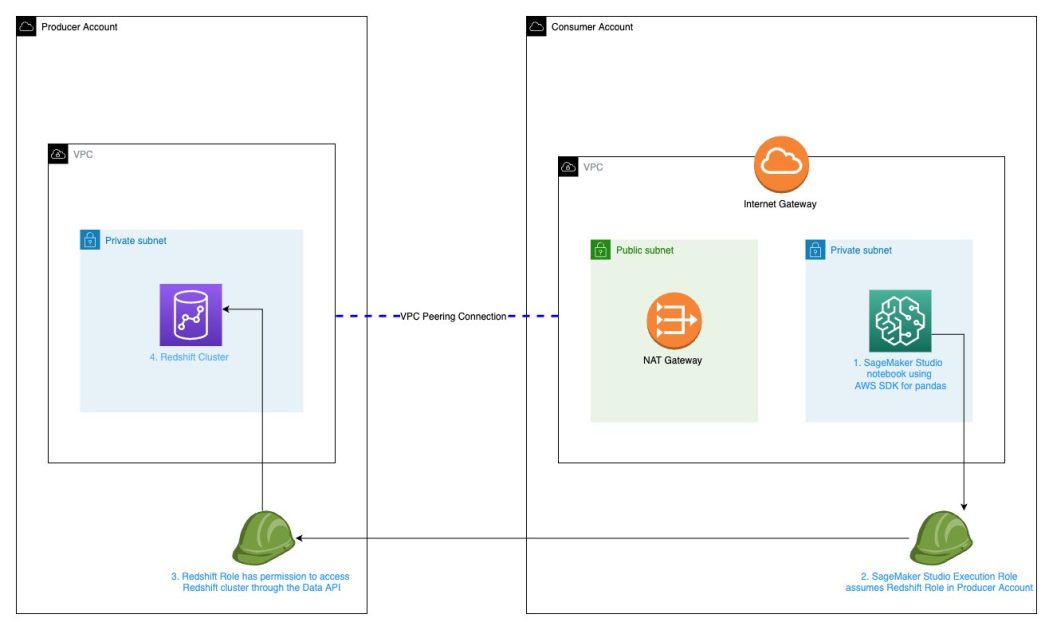
We start with two AWS accounts: a producer account with the Amazon Redshift data warehouse, and a consumer account for Amazon SageMaker ML use cases that has SageMaker Studio set up. The following is a high-level overview of the workflow:
- Set up SageMaker Studio with
VPCOnlymode in the consumer account. This prevents SageMaker from providing internet access to your studio notebooks. All SageMaker Studio traffic is through the specified VPC and subnets. - Update your SageMaker Studio domain to turn on
SourceIdentityto propagate the user profile name. - Create an AWS Identity and Access Management (IAM) role in the Amazon Redshift producer account that the SageMaker Studio IAM role will assume to access Amazon Redshift.
- Update the SageMaker IAM execution role in the SageMaker Studio consumer account that SageMaker Studio will use to assume the role in the producer Amazon Redshift account.
- Set up a peering connection between VPCs in the Amazon Redshift producer account and SageMaker Studio consumer account.
- Query Amazon Redshift in SageMaker Studio in the consumer account.
The following diagram illustrates our solution architecture.
Prerequisites
The steps in this post assume that Amazon Redshift is launched in a private subnet in the Amazon Redshift producer account. Launching Amazon Redshift in a private subnet provides an additional layer of security and isolation compared to launching it in a public subnet because the private subnet is not directly accessible from the internet and more secure from external attacks.
To download public libraries, you must create a VPC and a private and public subnet in the SageMaker consumer account. Then launch a NAT gateway in the public subnet and add an internet gateway for SageMaker Studio in the private subnet to access the internet. For instructions on how to establish a connection to a private subnet, refer to How do I set up a NAT gateway for a private subnet in Amazon VPC?
Set up SageMaker Studio with VPCOnly mode in the consumer account
To create SageMaker Studio with VPCOnly mode, complete the following steps:
- On the SageMaker console, choose Studio in the navigation pane.
- Launch SageMaker Studio, choose Standard setup, and choose Configure.

If you’re already using AWS IAM Identity Center (successor to AWS Single Sign-On) for accessing your AWS accounts, you can use it for authentication. Otherwise, you can use IAM for authentication and use your existing federated roles.
- In the General settings section, select Create a new role.
- In the Create an IAM role section, optionally specify your Amazon Simple Storage Service (Amazon S3) buckets by selecting Any, Specific, or None, then choose Create role.
This creates a SageMaker execution role, such as AmazonSageMaker-ExecutionRole-00000000.

- Under Network and Storage Section, choose your VPC, subnet (private subnet), and security group that you created as a prerequisite.
- Select VPC Only, then choose Next.

Update your SageMaker Studio domain to turn on SourceIdentity to propagate the user profile name
SageMaker Studio is integrated with AWS CloudTrail to enable administrators to monitor and audit user activity and API calls from SageMaker Studio notebooks. You can configure SageMaker Studio to record the user identity (specifically, the user profile name) to monitor and audit user activity and API calls from SageMaker Studio notebooks in CloudTrail events.
To log specific user activity among several user profiles, we recommended that you turn on SourceIdentity to propagate the SageMaker Studio domain with the user profile name. This allows you to persist the user information into the session so you can attribute actions to a specific user. This attribute is also persisted over when you chain roles, so you can get fine-grained visibility into their actions in the producer account. As of the time this post was written, you can only configure this using the AWS Command Line Interface (AWS CLI) or any command line tool.
To update this configuration, all apps in the domain must be in the Stopped or Deleted state.
Use the following code to enable the propagation of the user profile name as the SourceIdentity:

This requires that you add sts:SetSourceIdentity in the trust relationship for your execution role.
Create an IAM role in the Amazon Redshift producer account that SageMaker Studio must assume to access Amazon Redshift
To create a role that SageMaker will assume to access Amazon Redshift, complete the following steps:
- Open the IAM console in the Amazon Redshift producer account.

- Choose Roles in the navigation pane, then choose Create role.

- On the Select trusted entity page, select Custom trust policy.
- Enter the following custom trust policy into the editor and provide your SageMaker consumer account ID and the SageMaker execution role that you created:

- Choose Next.
- On the Add required permissions page, choose Create policy.
- Add the following sample policy and make necessary edits based on your configuration.

- Save the policy by adding a name, such as
RedshiftROAPIUserAccess.
The SourceIdentity attribute is used to tie the identity of the original SageMaker Studio user to the Amazon Redshift database user. The actions by the user in the producer account can then be monitored using CloudTrail and Amazon Redshift database audit logs.

- On the Name, review, and create page, enter a role name, review the settings, and choose Create role.

Update the IAM role in the SageMaker consumer account that SageMaker Studio assumes in the Amazon Redshift producer account
To update the SageMaker execution role for it to assume the role that we just created, complete the following steps:
- Open the IAM console in the SageMaker consumer account.
- Choose Roles in the navigation pane, then choose the SageMaker execution role that we created (
AmazonSageMaker-ExecutionRole-*). - In the Permissions policy section, on the Add permissions menu, choose Create inline policy.

- In the editor, on the JSON tab, enter the following policy, where <StudioRedshiftRoleARN> is the ARN of the role you created in the Amazon Redshift producer account:

You can get the ARN of the role created in the Amazon Redshift producer account on the IAM console, as shown in the following screenshot.

- Choose Review policy.
- For Name, enter a name for your policy.
- Choose Create policy.

Your permission policies should look similar to the following screenshot.

Set up a peering connection between the VPCs in the Amazon Redshift producer account and SageMaker Studio consumer account
To establish communication between the SageMaker Studio VPC and Amazon Redshift VPC, the two VPCs need to be peered using VPC peering. Complete the following steps to establish a connection:
- In either the Amazon Redshift or SageMaker account, open the Amazon VPC console.
- In the navigation pane, choose Peering connections, then choose Create peering connection.
- For Name, enter a name for your connection.
- Under Select a local VPC to peer with, choose a local VPC.
- Under Select another VPC to peer with, specify another VPC in the same Region and another account.
- Choose Create peering connection.

- Review the VPC peering connection and choose Accept request to activate.

After the VPC peering connection is successfully established, you create routes on both the SageMaker and Amazon Redshift VPCs to complete connectivity between them.
- In the SageMaker account, open the Amazon VPC console.
- Choose Route tables in the navigation pane, then choose the VPC that is associated with SageMaker and edit the routes.
- Add CIDR for the destination Amazon Redshift VPC and the target as the peering connection.
- Additionally, add a NAT gateway.
- Choose Save changes.

- In the Amazon Redshift account, open the Amazon VPC console.
- Choose Route tables in the navigation pane, then choose the VPC that is associated with Amazon Redshift and edit the routes.
- Add CIDR for the destination SageMaker VPC and the target as the peering connection.
- Additionally, add an internet gateway.
- Choose Save changes.

You can connect to SageMaker Studio from your VPC through an interface endpoint in your VPC instead of connecting over the internet. When you use a VPC interface endpoint, communication between your VPC and the SageMaker API or runtime is conducted entirely and securely within the AWS network.
- To create a VPC endpoint, in the SageMaker account, open the VPC console.
- Choose Endpoints in the navigation pane, then choose Create endpoint.
- Specify the SageMaker VPC, the respective subnets and appropriate security groups to allow inbound and outbound NFS traffic for your SageMaker notebooks domain, and choose Create VPC endpoint.

Query Amazon Redshift in SageMaker Studio in the consumer account
After all the networking has been successfully established, follow the steps in this section to connect to the Amazon Redshift cluster in the SageMaker Studio consumer account using the AWS SDK for pandas library:
- In SageMaker Studio, create a new notebook.
- If the AWS SDK for pandas package is not installed you can install it using the following:
This installation is not persistent and will be lost if the KernelGateway App is deleted. Custom packages can be added as part of a Lifecycle Configuration.
- Enter the following code in the first cell and run the code. Replace
RoleArnandregion_namevalues based on your account settings:
- Enter the following code in a new cell and run the code to get the current SageMaker user profile name:
- Enter the following code in a new cell and run the code:
To successfully query Amazon Redshift, your database administrator needs to assign the newly created user with the required read permissions within the Amazon Redshift cluster in the producer account.
- Enter the following code in a new cell, update the query to match your Amazon Redshift table, and run the cell. This should return the records successfully for further data processing and analysis.
You can now start building your data transformations and analysis based on your business requirements.
Clean up
To clean up any resources to avoid incurring recurring costs, delete the SageMaker VPC endpoints, Amazon Redshift cluster, and SageMaker Studio apps, users, and domain. Also delete any S3 buckets and objects you created.
Conclusion
In this post, we showed how to establish a cross-account connection between private Amazon Redshift and SageMaker Studio VPCs in different accounts using VPC peering and access Amazon Redshift data in SageMaker Studio using IAM role chaining, while also logging the user identity when the user accessed Amazon Redshift from SageMaker Studio. With this solution, you eliminate the need to manually move data between accounts to access data. We also walked through how to access the Amazon Redshift cluster using the AWS SDK for pandas library in SageMaker Studio and prepare the data for your ML use cases.
To learn more about Amazon Redshift and SageMaker, refer to the Amazon Redshift Database Developer Guide and Amazon SageMaker Documentation.
About the Authors
 Supriya Puragundla is a Senior Solutions Architect at AWS. She helps key customer accounts on their AI and ML journey. She is passionate about data-driven AI and the area of depth in machine learning.
Supriya Puragundla is a Senior Solutions Architect at AWS. She helps key customer accounts on their AI and ML journey. She is passionate about data-driven AI and the area of depth in machine learning.
 Marc Karp is a Machine Learning Architect with the Amazon SageMaker team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.
Marc Karp is a Machine Learning Architect with the Amazon SageMaker team. He focuses on helping customers design, deploy, and manage ML workloads at scale. In his spare time, he enjoys traveling and exploring new places.


