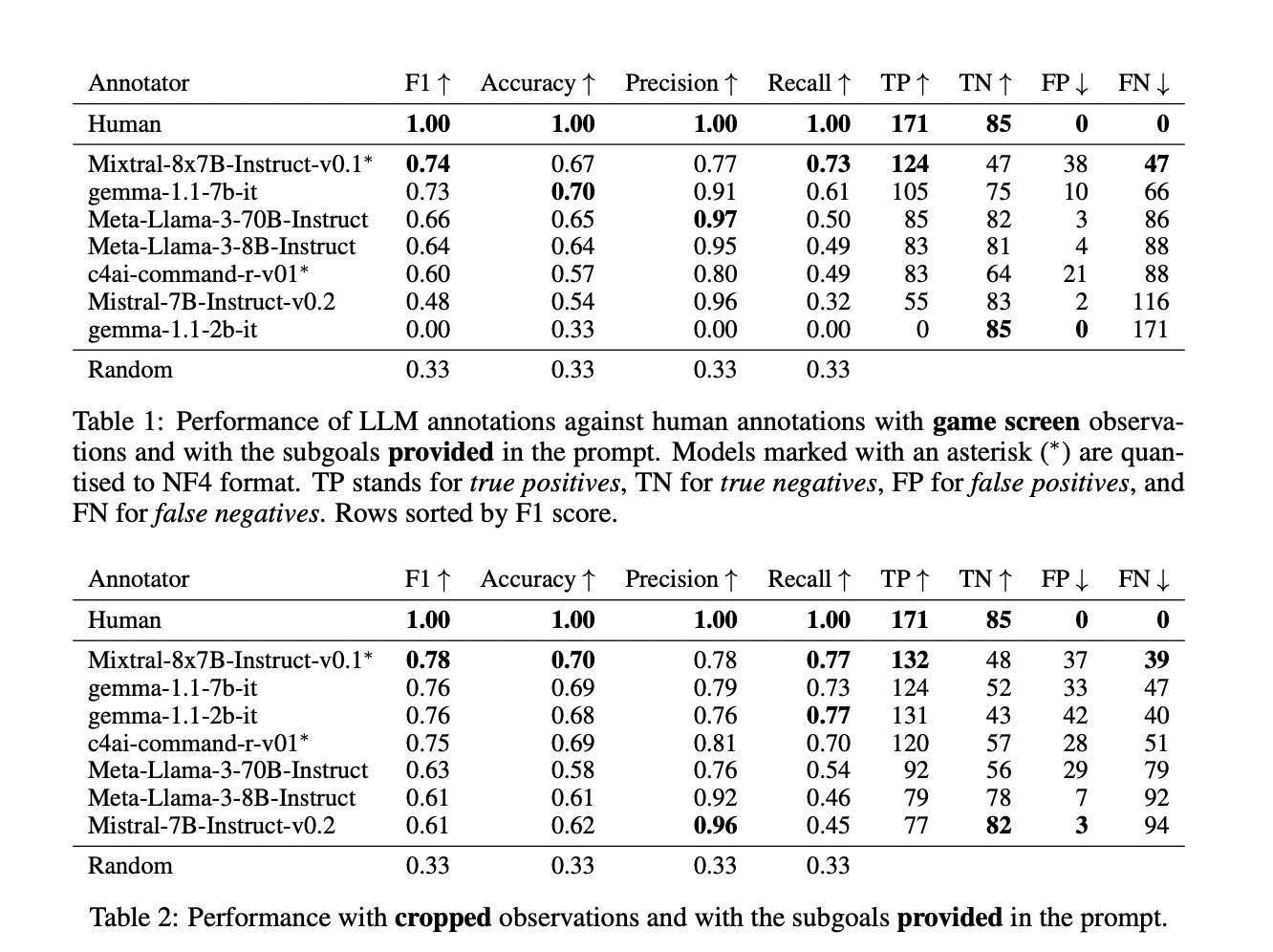
Reinforcement Learning (RL) continuously evolves as researchers explore methods to refine algorithms that learn from human feedback. This domain of learning algorithms deals with challenges in defining and optimizing reward functions critical for training models to perform various tasks ranging from gaming to language processing.
A prevalent issue in this area is the inefficient use of pre-collected datasets of human preferences, often overlooked in the RL training processes. Traditionally, these models are trained from scratch, ignoring existing datasets’ rich, informative content. This disconnect leads to inefficiencies and a lack of utilization of valuable, pre-existing knowledge. Recent advancements have introduced innovative methods that effectively integrate offline data into the RL training process to address this inefficiency.
Researchers from Cornell University, Princeton University, and Microsoft Research introduced a new algorithm, the Dataset Reset Policy Optimization (DR-PO) method. This method ingeniously incorporates preexisting data into the model training rule and is distinguished by its ability to reset directly to specific states from an offline dataset during policy optimization. It contrasts with traditional methods that begin every training episode from a generic initial state.
The DR-PO method enhances offline data by allowing the model to ‘reset’ to specific, beneficial states already identified as useful in the offline data. This process reflects real-world conditions where scenarios are not always initiated from scratch but are often influenced by prior events or states. By leveraging this data, DR-PO improves the efficiency of the learning process and broadens the application scope of the trained models.
DR-PO employs a hybrid strategy that blends online and offline data streams. This method capitalizes on the informative nature of the offline dataset by resetting the policy optimizer to states previously identified as valuable by human labelers. The integration of this method has demonstrated promising improvements over traditional techniques, which often disregard the potential insights available in pre-collected data.
DR-PO has shown outstanding results in studies involving tasks like TL;DR summarization and the Anthropic Helpful Harmful dataset. DR-PO has outperformed established methods like Proximal Policy Optimization (PPO) and Direction Preference Optimization (DPO). In the TL;DR summarization task, DR-PO achieved a higher GPT4 win rate, enhancing the quality of generated summaries. In head-to-head comparisons, DR-PO’s approach to integrating resets and offline data has consistently demonstrated superior performance metrics.

In conclusion, DR-PO presents a significant breakthrough in RL. DR-PO overcomes traditional inefficiencies by integrating pre-collected, human-preferred data into the RL training process. This method enhances learning efficiency by utilizing resets to specific states identified in offline datasets. Empirical evidence demonstrates that DR-PO surpasses conventional approaches such as Proximal Policy Optimization and Direction Preference Optimization in real-world applications like TL;DR summarization, achieving superior GPT4 win rates. This innovative approach streamlines the training process and maximizes the utility of existing human feedback, setting a new benchmark in adapting offline data for model optimization.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.