Motivated by the effective implementation of transformer architectures in natural language processing, machine learning researchers introduced the concept of a vision transformer (ViT) in 2021. This innovative approach serves as an alternative to convolutional neural networks (CNNs) for computer vision applications, as detailed in the paper, An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale.
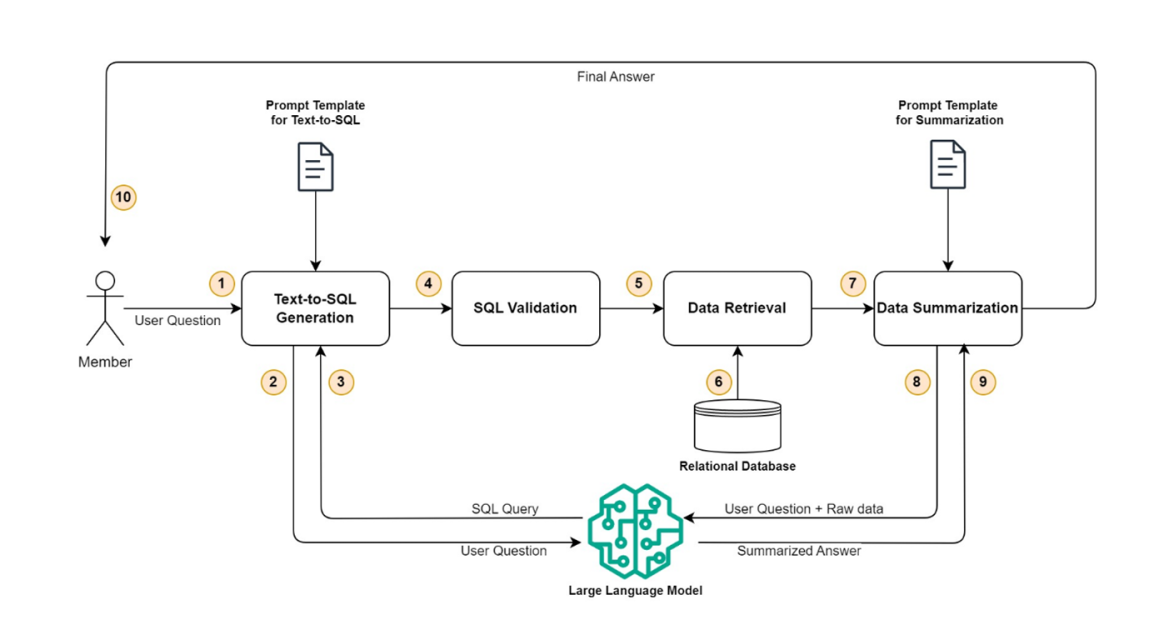
Since then, vision transformer architectures generally perform best on public benchmarks. Vision transformers can serve as the backbone for many publications, including image classification and object segmentation. Those applications enable great user experiences, like searching for a picture in the Photos app, measuring the size of a room with RoomPlan, or ARKIT semantic features, as referenced in our research highlight 3D Parametric Room Representation with RoomPlan.
We introduced efficient transformer deployment on the Apple Neural Engine (ANE) in our research highlight Deploying Transformers on the Apple Neural Engine. In this research highlight, we share new additions to support and augment the transformers on ANE. We use one vision transformer architecture as an example and introduce new principles to efficiently implement ANE-friendly vision transformers.
Faster Processing of High-Resolution Image Data
Due to the quadratic complexity of the attention module with regard to token length, global attention is inefficient on large token lengths with high-resolution image inputs as discussed in the paper Training Data-Efficient Image Transformers and Distillation Through Attention.
As a result, state-of-the-art vision transformers rely on local attention blocks, which improve their efficiency significantly. The attention mechanism is performed in each rectangular region that partitions an image, as seen in Figure 1. The information loss across local-attention windows is compensated for by cross-window information propagation through window shifting where images are split into patches, as discussed in the paper Swin Transformer: Hierarchial Vision Transformer Using Shifted Windows. Or, information loss can be compensated through depth-wise convolution layers, as outlined in MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models.
In this section, we will explore three key optimizations designed to enhance the performance of vision transformers:
- Perform a six-dimensional (6D) tensor window partition using a five-dimensional (5D) relayed partition.
- Run window partition/reverse operations with an NHWC tensor.
- Use alternative positional embedding to reduce file size and latency.
For this study, we use MOAT, which is defined as “a family of neural networks that build on top of Mobile convolution (for example, inverted residual blocks) and attention. MOAT is mobile-friendly and achieves state-of-the-art performance on public benchmarks.
Perform 6D tensor window partition using 5D relayed partition. ANE supports a maximum of 5D tensors. Although 5D is adequate for most functions, a typical window partition/reverse usually operates on 6D tensors (N, C, Nh, Nw, Hw, and Ww). N and C correspond to batch and channel numbers, Nh/Nw represents the number of windows for height and width dimensions and Hw/Ww represents the height and width of the windows. We relay the window partition process using only a 5D tensor to work around this constraint. We factor out only one dimension at a time: first, the height dimension, and then the width dimension.
We run the window partition/reverse operations with an NHWC tensor. Vision transformers that use local attention compute that attention within each window, significantly reducing latency. To implement local attention, the feature map must be efficiently partitioned into windows that do not overlap. After the attention computation is complete, a window reversal rearranges the windows into the normal feature map, and a window partition follows.
We noticed that the typical window partition/reverse operation implementation might be inefficient. This is because the ANE memory requires a 64-bytes alignment on last tensor dimension. In ANE, every 64-bytes of data of the last dimension is processed in the same batch, and if the last tensor dimension has less than the 64-bytes data, it will be padded to 64-bytes and processed in one batch. In the worst case, if the tensor has only 1 FP16 element per last dimension, it will be padded 32x larger to meet the 64-bytes alignment requirement, and the effective processing speed is 32x slower than the maximum allowed.
Therefore, to improve memory access efficiency, we chose to use NHWC as the tensor layout for window partition/reverse, instead of the most common NCHW layout. This is because the partitioned window size in the vision transformer is usually a small number, while the channel dimension size is usually a multiple of 32. When there’s an input resolution of 224×224, a common window size of 7×7, and the tensor layout is NCHW, the last dimension only contains seven elements — or 14-bytes — which then requires 50-bytes of data padding. Note that the tensor is only transposed and re-transposed back once, instead of looping on each partitioned window for efficiency.
Use alternative positional embedding to reduce file size and latency. Unlike convolutional neural networks, transformers lack inductive bias for encoding position information for tokens. Therefore, people often use position embedding (PE) to encode this information. Relative position embedding (RPE) is a type of PE that learns an attention-bias table and then adds it to the attention matrix. It is often used in state-of-the-art vision transformers like Swin Transformer and MOAT.
Thus, the size of RPE is token_len x token_len, or num_head x token_len x token_len for multihead attention. Since RPE grows quadratically when the token length is large, this learnable RPE table adds significant overhead to file size and latency. To reduce both, we replace the RPE with alternative position embedding.
We experimented with two approaches: single-head RPE and locally enhanced position embedding (LePE). For more on LePE, see Dong and team, CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows.
For single-head RPE, we restrict the number of RPE tables shared by different heads, which reduces the file size of the positional embedding to 1/num_heads of the original RPE.
For LePE, we add a depthwise convolution on the value tensor to encode the location information into the transformed value tensor. This adds a tiny learnable parameter of 3 x 3 x dim for each attention block, which is independent of token_len. In addition, we add a learnable absolute-position embedding table that is added to the input tensor instead of the attention matrix. The size of this table is 1 x token_len x dim, and it grows linearly with token_len. Therefore, LePE is significantly smaller than the size of RPE.
Now, we will briefly recap principles introduced in our research highlight, Deploying Transformers on the Apple Neural Engine:
- split_softmax
- Splitting on the softmax helps significantly reduce latency in the attention computation.
- Softmax is known to be slow and to have a quadratic complexity regarding token length. Various publications have discussed variants such as linear attention variants, CosFormer, and so on for dealing with this slowness. However, those variants come with a tradeoff of accuracy.
- Similar to the work in the paper “Deploying Transformers on the Apple Neural Engine,” we split the softmax to split the attention between attention heads, which increases the chance of L2 residency and parallelizes the computation for the softmax layer. This important technique makes the attention computation much faster.
- Use Conv2d 1×1 to replace linear layers. ANE runs convolution operations well, so replacing linear layers with convolution layers helps minimize ANE latency.
- Chunking Large query, key, and value tensors. One can split the QKV projection to increase the chance of L2 residency.
Comparison of Results from DeiT and MOAT Vision Transformers
We applied the three optimizations to two vision transformer architectures: DeiT and MOAT. Note that the optimizations we introduced apply to other vision transformer architectures, as well.
Figure 2 summarizes the model performance of DeiT/16-tiny and Tiny-MOAT-1, which are of similar size. DeiT is a typical vision transformer after applying all the optimization principles described in the document. MOAT has a similar number of parameters to DeiT. We can see that MOAT is significantly more efficient for higher input resolutions after our optimization.
We package our code with all the optimizations applied in the GitHub open source repository, including efficient visual attention components that can be reused as building blocks for new transformer architecture, as well as the reference implementation of MOAT.
As Figure 2 indicates, our optimized Tiny-MOAT-1 model is much faster than the third-party open-source implementation on ANE, and than the optimized DeiT/16 (tiny) model for high-resolution inputs (512×512). Also, Tiny-MOAT-1 achieves higher accuracy on the ImageNet dataset.
Model Export Walk-Through
In this section, we demonstrate how to apply these optimizations with Core ML tools and build the model using specified hyperparameters.
import torch
import coremltools as ct
from vision_transformers.attention_utils import (
PEType,
)
from vision_transformers.model import _build_model
def moat_export(
base_arch="tiny-moat-1",
shape=(1, 3, 256, 256),
pe_type=PEType.LePE_ADD,
attention_mode="local",
):
split_head = True
batch = shape[0]
pe_type = pe_type if "moat" in base_arch else "ape"
attention_mode = attention_mode if "moat" in base_arch else "global"
local_window_size = [8, 8] if attention_mode == "local" else None
if "tiny-moat" in base_arch:
_, model = _build_model(
base_arch=base_arch,
shape=shape,
split_head=split_head,
pe_type=pe_type,
channel_buffer_align=False,
attention_mode=attention_mode,
local_window_size=local_window_size,
)
resolution = f"{shape[-2]}x{shape[-1]}"
We initialize a tensor and jit.trace the model. Then, we use the coremltools Python package to export the outcome into an mlpackage that can be used for profiling and deploying the model.
x = torch.rand(shape)
with torch.no_grad():
model.eval()
traced_optimized_model = torch.jit.trace(model, (x,))
ane_mlpackage_obj = ct.convert(
traced_optimized_model,
convert_to="mlprogram",
inputs=[
ct.TensorType("x", shape=x.shape),
],
)
out_name = f"{base_arch}_{attention_mode}Attn_batch{batch}_{resolution}_{pe_type}_split-head_{split_head}"
out_path = f"./exported_model/{out_name}.mlpackage"
ane_mlpackage_obj.save(out_path)
After exporting the ML package illustrated above, load the mlpackage to your XCode and run profiling. This gives you the profiling tab show below in Figure 3.
Conclusion
Vision transformers are integral for computer vision applications. In this research highlight, we shared our learnings for optimizing and deploying attention-based vision transformers whose implementation is highly friendly to the ANE. We hope ML developers and researchers can apply similar principles when designing their own vision transformer architectures, in order for them to build applications that run efficiently on Apple devices.
Acknowledgments
Many people contributed to this work, including De Wang, Eshan Verma, Fuxin Li, Haris Baig, Jinmook Lee, Matthew Kay Fei Lee, Patrick Dong, Qi Shan, Rui Li, Sung Hee Park, Youchang Kim, Yuyan Li, Zheng Li, and Zhile Ren.
Apple Resources
Apple Developer. n.d. “Machine Learning: Core ML.” [link.]
Apple Github Repository. “Apple Neural Engine (ANE) Transformers.” [link.]
Apple Machine Learning Research. 2022. “Deploying Transformers on the Apple Neural Engine.” [link.]
Apple Machine Learning Research. 2023. “Learning Iconic Scenes with Differential Privacy.” [link.]
Apple Machine Learning Research. 2023. “3D Parametric Room Representation with RoomPlan”, [link.]
Apple Machine Learning Research. 2023. “Fast Class-Agnostic Salient Object Segmentation” [link.]
External References
Dong, Xiaoyi, Jianmin Bao, Dongdong Chen, Weiming Zhang, Nenghai Yu, Lu Yuan, Dong Chen, and Baining Guo. 2021. “CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows,” July. [link.]
Dosovitskiy, Alexey, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, et al. 2022. “An Image Is Worth 16×16 Words: Transformers for Image Recognition at Scale.” Openreview.net. March. [link.]
Liu, Ze, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. 2021. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” March. [link.]
Touvron, Hugo, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. “Training Data-Efficient Image Transformers & Distillation through Attention.” January. [link.]
Yang, Chao, Siyuan Qiao, Qihang Yu, Xiaoding Yuan, Yiyong Zhu, Alan Yuille, Hartwig Adam, and Liang-Chieh Chen. 2022. “MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models.” October. [link.]
Touvron, Hugo, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. 2021. “Training Data-Efficient Image Transformers & Distillation through Attention.” January. [link.]
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining
Guo. 2021. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” March. [link.]