To train agents to interact well with humans, we need to be able to measure progress. But human interaction is complex and measuring progress is difficult. In this work we developed a method, called the Standardised Test Suite (STS), for evaluating agents in temporally extended, multi-modal interactions. We examined interactions that consist of human participants asking agents to perform tasks and answer questions in a 3D simulated environment.
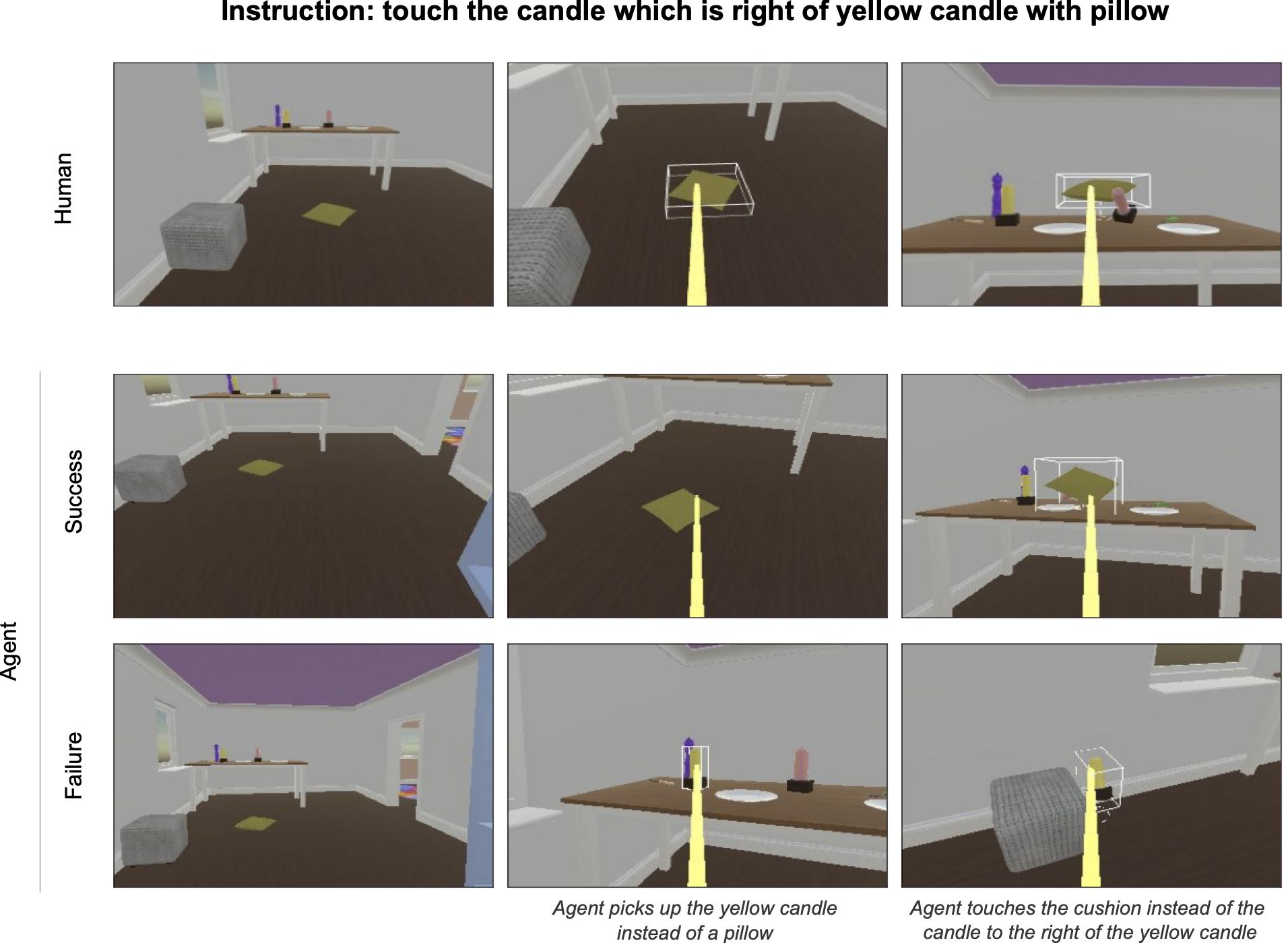
The STS methodology places agents in a set of behavioural scenarios mined from real human interaction data. Agents see a replayed scenario context, receive an instruction, and are then given control to complete the interaction offline. These agent continuations are recorded and then sent to human raters to annotate as success or failure. Agents are then ranked according to the proportion of scenarios on which they succeed.
Many of the behaviours that are second nature to humans in our day-to-day interactions are difficult to put into words, and impossible to formalise. Thus, the mechanism relied on for solving games (like Atari, Go, DotA, and Starcraft) with reinforcement learning won’t work when we try to teach agents to have fluid and successful interactions with humans. For example, think about the difference between these two questions: “Who won this game of Go?” versus “What are you looking at?” In the first case, we can write a piece of computer code that counts the stones on the board at the end of the game and determines the winner with certainty. In the second case, we have no idea how to codify this: the answer may depend on the speakers, the size and shapes of the objects involved, whether the speaker is joking, and other aspects of the context in which the utterance is given. Humans intuitively understand the myriad of relevant factors involved in answering this seemingly mundane question.
Interactive evaluation by human participants can serve as a touchstone for understanding agent performance, but this is noisy and expensive. It is difficult to control the exact instructions that humans give to agents when interacting with them for evaluation. This kind of evaluation is also in real-time, so it is too slow to rely on for swift progress. Previous works have relied on proxies to interactive evaluation. Proxies, such as losses and scripted probe tasks (e.g. “lift the x” where x is randomly selected from the environment and the success function is painstakingly hand-crafted), are useful for gaining insight into agents quickly, but don’t actually correlate that well with interactive evaluation. Our new method has advantages, mainly affording control and speed to a metric that closely aligns with our ultimate goal – to create agents that interact well with humans.
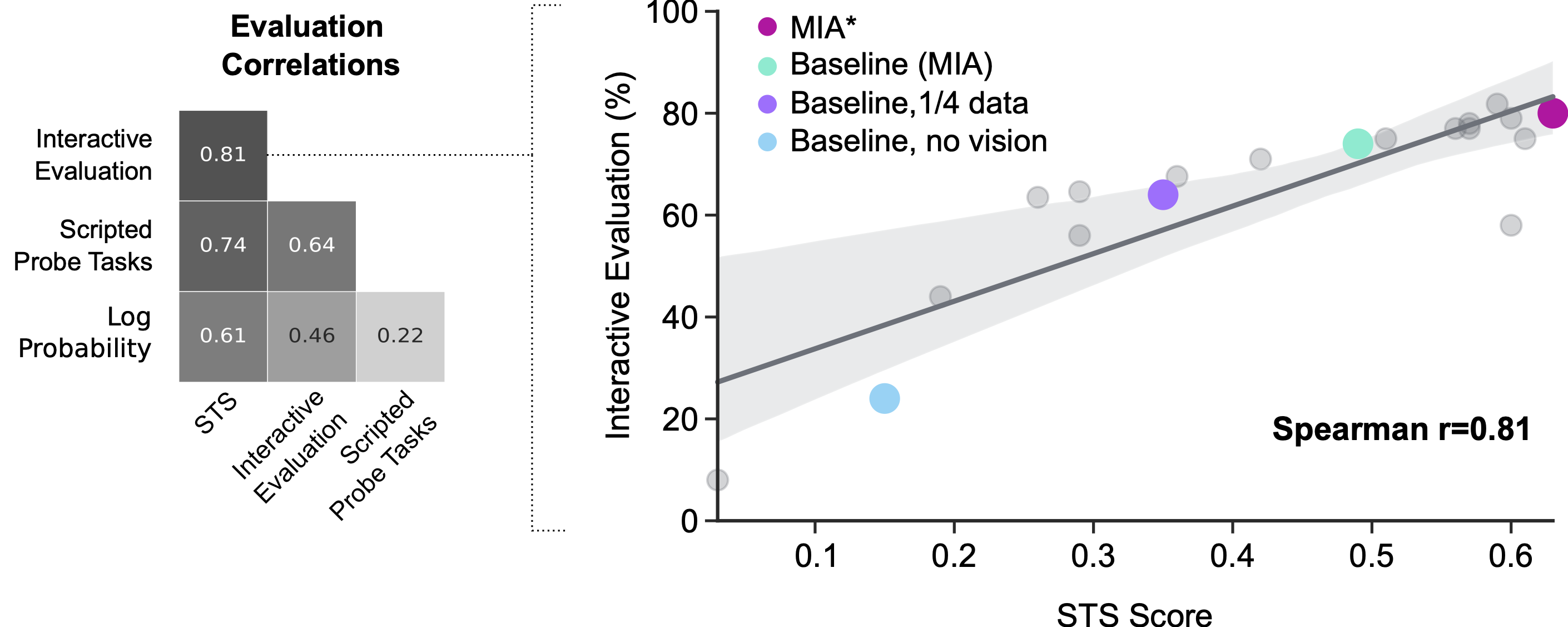
The development of MNIST, ImageNet and other human-annotated datasets has been essential for progress in machine learning. These datasets have allowed researchers to train and evaluate classification models for a one-time cost of human inputs. The STS methodology aims to do the same for human-agent interaction research. This evaluation method still requires humans to annotate agent continuations; however, early experiments suggest that automation of these annotations may be possible, which would enable fast and effective automated evaluation of interactive agents. In the meantime, we hope that other researchers can use the methodology and system design to accelerate their own research in this area.