The current design of causal language models, such as GPTs, is intrinsically burdened with the challenge of semantic coherence over longer stretches because of their one-token-ahead prediction design. This has enabled significant generative AI development but often leads to “topic drift” when longer sequences are produced since each token predicted depends only on the presence of mere preceding tokens, not from a broader perspective. This narrows the practical usefulness of these models in complex real-world applications with strict topic adherence, such as narrative generation, content creation, and coding tasks. Overcoming this challenge by enabling multi-token prediction would greatly improve semantic continuity, accuracy, and coherence of the generated sequences of the current generative language models.
There have been various ways through which multi-token prediction has been addressed, each with different limitations. Models that aim to make predictions for multiple tokens by splitting embeddings or having multiple language heads are computationally intensive and often don’t perform well. For Seq2Seq models in encoder-decoder sets, while this allows for multi-token prediction, they fail to capture past contexts into one single embedding; hence, a lot of inefficiencies result. While BERT and other masked language models can predict multiple tokens of a sequence that are masked, they fail in left-to-right generation, hence restricting their use in sequential text prediction. ProphetNet, on the other hand, uses an n-gram prediction strategy; nonetheless, this is not flexible across a wide range of data types. The basic drawbacks of the aforementioned methods are scalability issues, computational waste, and generally unimpressive results while generating high-quality predictions over long-context problems.
The researchers from EPFL introduce the Future Token Prediction model, representing a new architecture to create broader context-aware token embeddings. This will enable seamless multi-token predictions where, in contrast with standard models, the embedding from the top layers is used by a transformer encoder to provide “pseudo-sequences” cross-attended by a small transformer decoder for next-token predictions. In this way, the model leverages such encoder-decoder capability of the FTP for retaining context information from tokens of the previous history to make smoother transitions and maintain topic coherence across multi-token predictions. With more widespread sequence context encoded within its embeddings, FTP provides stronger continuity for generated sequences and has become one of the best approaches to content generation and other applications that require long-form semantic coherence.
The FTP model employs a modified GPT-2 architecture that is made up of a 12-layer encoder with a 3-layer decoder. Its encoder generates token embeddings that are linearly projected to higher dimensionality into a 12-dimensional pseudo-sequence that the decoder cross-attends over to make sense of sequence context. It shares embedding weights between the encoder and decoder; it is trained on OpenWebText data and uses the GPT-2 tokenizer. Meanwhile, optimization is done by AdamW, with a batch size of 500 and a learning rate of 4e-4. There is the gamma parameter set to 0.8 in this model to progressively discount the attention given to tokens far into the future so that immediate predictions can remain highly accurate. This way, the FTP model manages to keep semantic coherence without substantial computational overhead and thus finds an optimum trade-off between efficiency and performance.
These results and evaluation indeed show that the model brings significant improvements compared to traditional GPTs on many key performance metrics: significant reductions in perplexity, better predictive accuracy, and enhanced stability for long-sequence tasks. It also yields higher recall, precision, and F1 scores in BERT-based assessments of textual quality, which would further imply improved semantic alignment against actual text sequences. It also outperforms GPT models on text classification tasks like the IMDB and Amazon reviews and always provides better validation loss with higher accuracy. More importantly, FTP follows the topic of the generated text more coherently, supported by higher cosine similarity scores in long-sequence evaluations, further establishing its prowess for coherent, contextually relevant content generation across more varied applications.
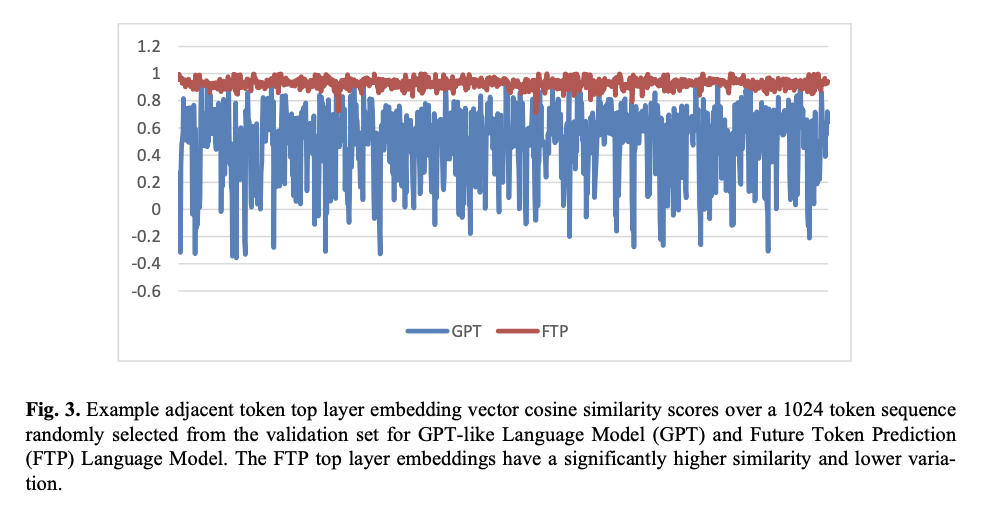
The FTP model represents a paradigm shift in causal language modeling, one that develops the most critical inefficiencies of the classic single-token methods into an embedding that supports wider and context-sensitive views for making multi-token predictions. By enhancing both the accuracy of prediction and semantic coherence, this difference is underlined by improved scores across both perplexity and BERT-based metrics for a wide range of tasks. The pseudo-sequence cross-attention mechanism within this model enhances generative AI by pulling consistent narrative flow—an important requirement for high value in topic-coherent language modeling across applications that require semantic integrity.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Trending] LLMWare Introduces Model Depot: An Extensive Collection of Small Language Models (SLMs) for Intel PCs
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.