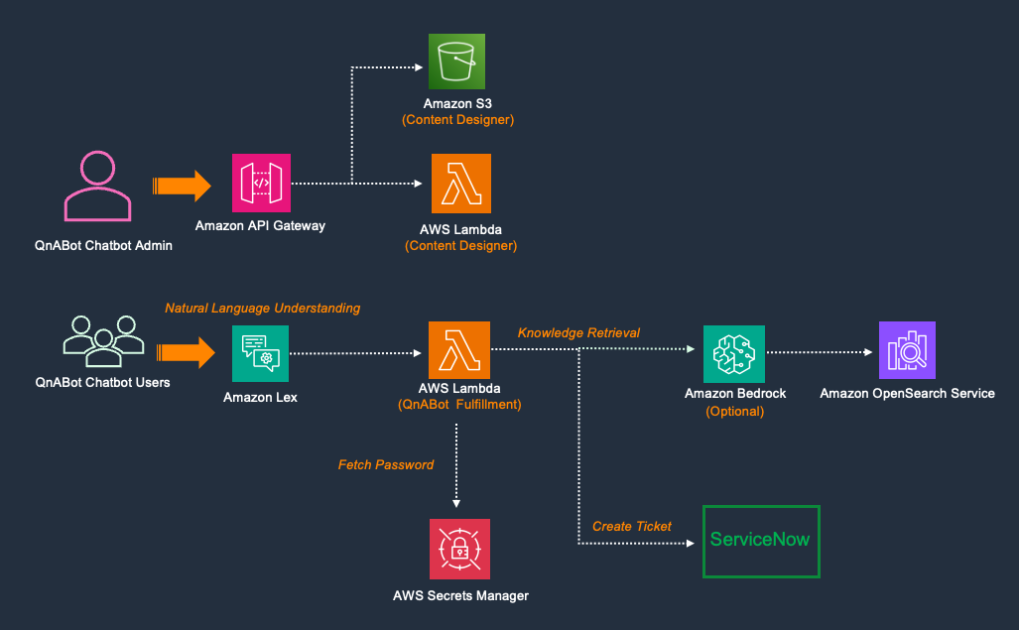
Generative AI has opened up a lot of potential in the field of AI. We are seeing numerous uses, including text generation, code generation, summarization, translation, chatbots, and more. One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language. The primary goal is to automatically generate SQL queries from natural language text. To do this, the text input is transformed into a structured representation, and from this representation, a SQL query that can be used to access a database is created.
In this post, we provide an introduction to text to SQL (Text2SQL) and explore use cases, challenges, design patterns, and best practices. Specifically, we discuss the following:
- Why do we need Text2SQL
- Key components for Text to SQL
- Prompt engineering considerations for natural language or Text to SQL
- Optimizations and best practices
- Architecture patterns
Why do we need Text2SQL?
Today, a large amount of data is available in traditional data analytics, data warehousing, and databases, which may be not easy to query or understand for the majority of organization members. The primary goal of Text2SQL is to make querying databases more accessible to non-technical users, who can provide their queries in natural language.
NLP SQL enables business users to analyze data and get answers by typing or speaking questions in natural language, such as the following:
- “Show total sales for each product last month”
- “Which products generated more revenue?”
- “What percentage of customers are from each region?”
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) via a single API, enabling to easily build and scale Gen AI applications. It can be leveraged to generate SQL queries based on questions similar to the ones listed above and query organizational structured data and generate natural language responses from the query response data.
Key components for text to SQL
Text-to-SQL systems involve several stages to convert natural language queries into runnable SQL:
- Natural language processing:
- Analyze the user’s input query
- Extract key elements and intent
- Convert to a structured format
- SQL generation:
- Map extracted details into SQL syntax
- Generate a valid SQL query
- Database query:
- Run the AI-generated SQL query on the database
- Retrieve results
- Return results to the user
One remarkable capability of Large Language Models (LLMs) is generation of code, including Structured Query Language (SQL) for databases. These LLMs can be leveraged to understand the natural language question and generate a corresponding SQL query as an output. The LLMs will benefit by adopting in-context learning and fine-tuning settings as more data is provided.
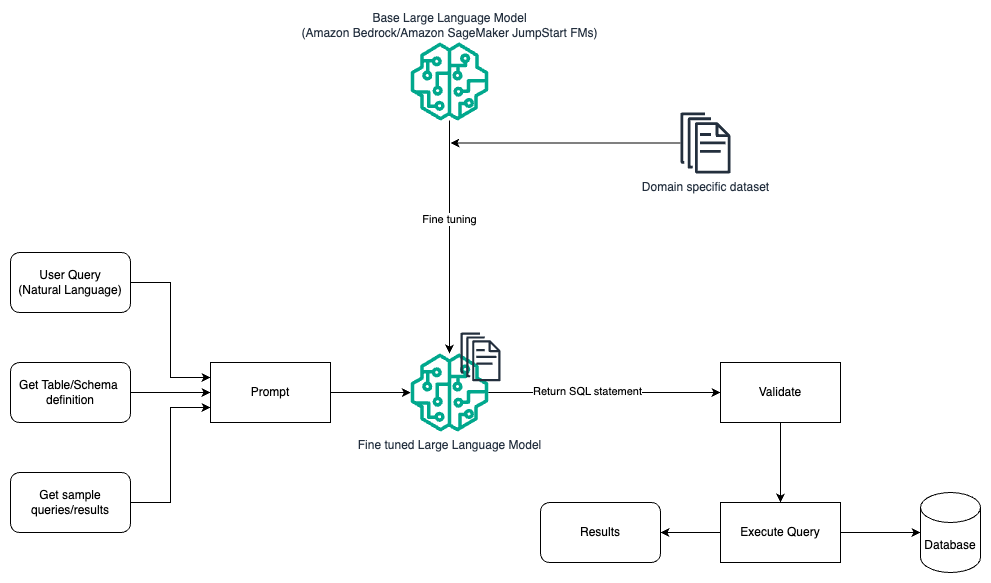
The following diagram illustrates a basic Text2SQL flow.
Prompt engineering considerations for natural language to SQL
The prompt is crucial when using LLMs to translate natural language into SQL queries, and there are several important considerations for prompt engineering.
Effective prompt engineering is key to developing natural language to SQL systems. Clear, straightforward prompts provide better instructions for the language model. Providing context that the user is requesting a SQL query along with relevant database schema details enables the model to translate the intent accurately. Including a few annotated examples of natural language prompts and corresponding SQL queries helps guide the model to produce syntax-compliant output. Additionally, incorporating Retrieval Augmented Generation (RAG), where the model retrieves similar examples during processing, further improves the mapping accuracy. Well-designed prompts that give the model sufficient instruction, context, examples, and retrieval augmentation are crucial for reliably translating natural language into SQL queries.
The following is an example of a baseline prompt with code representation of the database from the whitepaper Enhancing Few-shot Text-to-SQL Capabilities of Large Language Models: A Study on Prompt Design Strategies.
As illustrated in this example, prompt-based few-shot learning provides the model with a handful of annotated examples in the prompt itself. This demonstrates the target mapping between natural language and SQL for the model. Typically, the prompt would contain around 2–3 pairs showing a natural language query and the equivalent SQL statement. These few examples guide the model to generate syntax-compliant SQL queries from natural language without requiring extensive training data.
Fine-tuning vs. prompt engineering
When building natural language to SQL systems, we often get into the discussion of if fine-tuning the model is the right technique or if effective prompt engineering is the way to go. Both approaches could be considered and selected based on the right set of requirements:
-
- Fine-tuning – The baseline model is pre-trained on a large general text corpus and then can use instruction-based fine-tuning, which uses labeled examples to improve the performance of a pre-trained foundation model on text-SQL. This adapts the model to the target task. Fine-tuning directly trains the model on the end task but requires many text-SQL examples. You can use supervised fine-tuning based on your LLM to improve the effectiveness of text-to-SQL. For this, you can use several datasets like Spider, WikiSQL, CHASE, BIRD-SQL, or CoSQL.
- Prompt engineering – The model is trained to complete prompts designed to prompt the target SQL syntax. When generating SQL from natural language using LLMs, providing clear instructions in the prompt is important for controlling the model’s output. In the prompt to annotate different components like pointing to columns, schema and then instruct which type of SQL to create. These act like instructions that tell the model how to format the SQL output. The following prompt shows an example where you point table columns and instruct to create a MySQL query:
An effective approach for text-to-SQL models is to first start with a baseline LLM without any task-specific fine-tuning. Well-crafted prompts can then be used to adapt and drive the base model to handle the text-to-SQL mapping. This prompt engineering allows you to develop the capability without needing to do fine-tuning. If prompt engineering on the base model doesn’t achieve sufficient accuracy, fine-tuning on a small set of text-SQL examples can then be explored along with further prompt engineering.
The combination of fine-tuning and prompt engineering may be required if prompt engineering on the raw pre-trained model alone doesn’t meet requirements. However, it’s best to initially attempt prompt engineering without fine-tuning, because this allows rapid iteration without data collection. If this fails to provide adequate performance, fine-tuning alongside prompt engineering is a viable next step. This overall approach maximizes efficiency while still allowing customization if purely prompt-based methods are insufficient.
Optimization and best practices
Optimization and best practices are essential for enhancing effectiveness and ensuring resources are used optimally and the right results are achieved in the best way possible. The techniques help in improving performance, controlling costs, and achieving a better-quality outcome.
When developing text-to-SQL systems using LLMs, optimization techniques can improve performance and efficiency. The following are some key areas to consider:
- Caching – To improve latency, cost control, and standardization, you can cache the parsed SQL and recognized query prompts from the text-to-SQL LLM. This avoids reprocessing repeated queries.
- Monitoring – Logs and metrics around query parsing, prompt recognition, SQL generation, and SQL results should be collected to monitor the text-to-SQL LLM system. This provides visibility for the optimization example updating the prompt or revisiting the fine-tuning with an updated dataset.
- Materialized views vs. tables – Materialized views can simplify SQL generation and improve performance for common text-to-SQL queries. Querying tables directly may result in complex SQL and also result in performance issues, including constant creation of performance techniques like indexes. Additionally, you can avoid performance issues when the same table is used for other areas of application at the same time.
- Refreshing data – Materialized views need to be refreshed on a schedule to keep data current for text-to-SQL queries. You can use batch or incremental refresh approaches to balance overhead.
- Central data catalog – Creating a centralized data catalog provides a single pane of glass view to an organization’s data sources and will help LLMs select appropriate tables and schemas in order to provide more accurate responses. Vector embeddings created from a central data catalog can be supplied to an LLM along with information requested to generate relevant and precise SQL responses.
By applying optimization best practices like caching, monitoring, materialized views, scheduled refreshing, and a central catalog, you can significantly improve the performance and efficiency of text-to-SQL systems using LLMs.
Architecture patterns
Let’s look at some architecture patterns that can be implemented for a text to SQL workflow.
Prompt engineering
The following diagram illustrates the architecture for generating queries with an LLM using prompt engineering.

In this pattern, the user creates a prompt-based few-shot learning that provides the model with annotated examples in the prompt itself, which includes the table and schema details and some sample queries with its results. The LLM uses the provided prompt to return back the AI generated SQL which is validated and run against the database to get the results. This is the most straightforward pattern to get started using prompt engineering. For this, you can use Amazon Bedrock which is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI or JumpStart Foundation Models which offers state-of-the-art foundation models for use cases such as content writing, code generation, question answering, copywriting, summarization, classification, information retrieval, and more
Prompt engineering and fine-tuning
The following diagram illustrates the architecture for generating queries with an LLM using prompt engineering and fine-tuning.

This flow is similar to the previous pattern, which mostly relies on prompt engineering, but with an additional flow of fine-tuning on the domain-specific dataset. The fine-tuned LLM is used to generate the SQL queries with minimal in-context value for the prompt. For this, you can use SageMaker JumpStart to fine-tune an LLM on a domain-specific dataset in the same way you would train and deploy any model on Amazon SageMaker.
Prompt engineering and RAG
The following diagram illustrates the architecture for generating queries with an LLM using prompt engineering and RAG.

In this pattern, we use Retrieval Augmented Generation using vector embeddings stores, like Amazon Titan Embeddings or Cohere Embed, on Amazon Bedrock from a central data catalog, like AWS Glue Data Catalog, of databases within an organization. The vector embeddings are stored in vector databases like Vector Engine for Amazon OpenSearch Serverless, Amazon Relational Database Service (Amazon RDS) for PostgreSQL with the pgvector extension, or Amazon Kendra. LLMs use the vector embeddings to select the right database, tables, and columns from tables faster when creating SQL queries. Using RAG is helpful when data and relevant information that need to be retrieved by LLMs are stored in multiple separate database systems and the LLM needs to be able to search or query data from all these different systems. This is where providing vector embeddings of a centralized or unified data catalog to the LLMs results in more accurate and comprehensive information returned by the LLMs.
Conclusion
In this post, we discussed how we can generate value from enterprise data using natural language to SQL generation. We looked into key components, optimization, and best practices. We also learned architecture patterns from basic prompt engineering to fine-tuning and RAG. To learn more, refer to Amazon Bedrock to easily build and scale generative AI applications with foundation models
About the Authors
 Randy DeFauw is a Senior Principal Solutions Architect at AWS. He holds an MSEE from the University of Michigan, where he worked on computer vision for autonomous vehicles. He also holds an MBA from Colorado State University. Randy has held a variety of positions in the technology space, ranging from software engineering to product management. In entered the Big Data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon.
Randy DeFauw is a Senior Principal Solutions Architect at AWS. He holds an MSEE from the University of Michigan, where he worked on computer vision for autonomous vehicles. He also holds an MBA from Colorado State University. Randy has held a variety of positions in the technology space, ranging from software engineering to product management. In entered the Big Data space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon.
 Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
Nitin Eusebius is a Sr. Enterprise Solutions Architect at AWS, experienced in Software Engineering, Enterprise Architecture, and AI/ML. He is deeply passionate about exploring the possibilities of generative AI. He collaborates with customers to help them build well-architected applications on the AWS platform, and is dedicated to solving technology challenges and assisting with their cloud journey.
 Arghya Banerjee is a Sr. Solutions Architect at AWS in the San Francisco Bay Area focused on helping customers adopt and use AWS Cloud. Arghya is focused on Big Data, Data Lakes, Streaming, Batch Analytics and AI/ML services and technologies.
Arghya Banerjee is a Sr. Solutions Architect at AWS in the San Francisco Bay Area focused on helping customers adopt and use AWS Cloud. Arghya is focused on Big Data, Data Lakes, Streaming, Batch Analytics and AI/ML services and technologies.