This post is co-written with Pradeep Prabhakaran from Cohere.
Retrieval Augmented Generation (RAG) is a powerful technique that can help enterprises develop generative artificial intelligence (AI) apps that integrate real-time data and enable rich, interactive conversations using proprietary data.
RAG allows these AI applications to tap into external, reliable sources of domain-specific knowledge, enriching the context for the language model as it answers user queries. However, the reliability and accuracy of the responses hinges on finding the right source materials. Therefore, honing the search process in RAG is crucial to boosting the trustworthiness of the generated responses.
RAG systems are important tools for building search and retrieval systems, but they often fall short of expectations due to suboptimal retrieval steps. This can be enhanced using a rerank step to improve search quality.
RAG is an approach that combines information retrieval techniques with natural language processing (NLP) to enhance the performance of text generation or language modeling tasks. This method involves retrieving relevant information from a large corpus of text data and using it to augment the generation process. The key idea is to incorporate external knowledge or context into the model to improve the accuracy, diversity, and relevance of the generated responses.
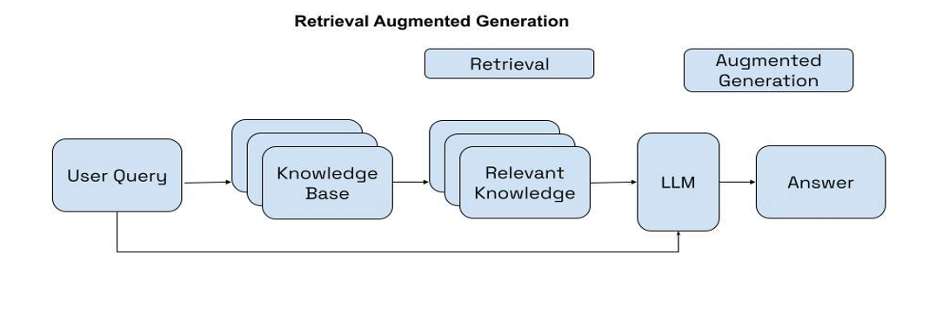
Workflow of RAG Orchestration
The RAG orchestration generally consists of two steps:
- Retrieval – RAG fetches relevant documents from an external data source using the generated search queries. When presented with the search queries, the RAG-based application searches the data source for relevant documents or passages.
- Grounded generation – Using the retrieved documents or passages, the generation model creates educated answers with inline citations using the fetched documents.
The following diagram shows the RAG workflow.
Document retrieval in RAG orchestration
One technique for retrieving documents in a RAG orchestration is dense retrieval, which is an approach to information retrieval that aims to understand the semantic meaning and intent behind user queries. Dense retrieval finds the closest documents to a user query in the embedding, as shown in the following screenshot.

The goal of dense retrieval is to map both the user queries and documents (or passages) into a dense vector space. In this space, the similarity between the query and document vectors can be computed using standard distance metrics like cosine similarity or euclidean distance. The documents that match closest to the semantic meaning of the user query based on the calculated distance metrics are then presented back to the user.
The quality of the final responses to search queries is significantly influenced by the relevance of the retrieved documents. While dense retrieval models are very efficient and can scale to large datasets, they struggle with more complex data and questions due to the simplicity of the method. Document vectors contain the meaning of text in a compressed representation—typically 786-1536 dimension vectors. This often results in loss of information because information is compressed into a single vector. When documents are retrieved during a vector search the most relevant information is not always presented at the top of the retrieval.
Boost search accuracy with Cohere Rerank
To address the challenges with accuracy, search engineers have used two-stage retrieval as a means of increasing search quality. In these two-stage systems, a first-stage model (an embedding model or retriever) retrieves a set of candidate documents from a larger dataset. Then, a second-stage model (the reranker) is used to rerank those documents retrieved by the first-stage model.
A reranking model, such as Cohere Rerank, is a type of model that will output a similarity score when given a query and document pair. This score can be used to reorder the documents that are most relevant to the search query. Among the reranking methodologies, the Cohere Rerank model stands out for its ability to significantly enhance search accuracy. The model diverges from traditional embedding models by employing deep learning to evaluate the alignment between each document and the query directly. Cohere Rerank outputs a relevance score by processing the query and document in tandem, which results in a more nuanced document selection process.
In the following example, the application was presented with a query: “When was the transformer paper coauthored by Aidan Gomez published?” The top-k with k = 6 returned the results shown in the image, in which the retrieved result set did contain the most accurate result, although it was at the bottom of the list. With k = 3, the most relevant document would not be included in the retrieved results.

Cohere Rerank aims to reassess and reorder the relevance of the retrieved documents based on additional criteria, such as semantic content, user intent, and contextual relevance, to output a similarity score. This score is then used to reorder the documents by relevance of the query. The following image shows reorder results using Rerank.

By applying Cohere Rerank after the first-stage retrieval, the RAG orchestration can gain the benefits of both approaches. While first-stage retrieval helps to capture relevant items based on proximity matches within the vector space, reranking helps optimize search according to results by guaranteeing contextually relevant results are surfaced to the top. The following diagram demonstrates this improved efficiency.

The latest version of Cohere Rerank, Rerank 3, is purpose-built to enhance enterprise search and RAG systems. Rerank 3 offers state-of-the-art capabilities for enterprise search, including:
- 4k context length to significantly improve search quality for longer documents
- Ability to search over multi-aspect and semi-structured data (such as emails, invoices, JSON documents, code, and tables)
- Multilingual coverage of more than 100 languages
- Improved latency and lower total cost of ownership (TCO)
The endpoint takes in a query and a list of documents, and it produces an ordered array with each document assigned a relevance score. This provides a powerful semantic boost to the search quality of any keyword or vector search system without requiring any overhaul or replacement.
Developers and businesses can access Rerank on Cohere’s hosted API and on Amazon SageMaker. This post offers a step-by-step walkthrough of consuming Cohere Rerank on Amazon SageMaker.
Solution overview
This solution follows these high-level steps:
- Subscribe to the model package
- Create an endpoint and perform real-time inference
Prerequisites
For this walkthrough, you must have the following prerequisites:
- The cohere-aws notebook.
This is a reference notebook, and it cannot run unless you make changes suggested in the notebook. It contains elements that render correctly in the Jupyter interface, so you need to open it from an Amazon SageMaker notebook instance or in Amazon SageMaker Studio.
- An AWS Identity and Access Management (IAM) role with the AmazonSageMakerFullAccess policy attached. To deploy this machine learning (ML) model successfully, choose one of the following options:
- If your AWS account does not have a subscription to Cohere Rerank 3 Model – Multilingual, your IAM role needs to have the following three permissions, and you need to have the authority to make AWS Marketplace subscriptions in the AWS account used:
aws-marketplace:ViewSubscriptionsaws-marketplace:Unsubscribeaws-marketplace:Subscribe
- If your AWS account has a subscription to Cohere Rerank 3 Model – Multilingual, you can skip the instructions for subscribing to the model package.
- If your AWS account does not have a subscription to Cohere Rerank 3 Model – Multilingual, your IAM role needs to have the following three permissions, and you need to have the authority to make AWS Marketplace subscriptions in the AWS account used:
Refrain from using full access in production environments. Security best practice is to opt for the principle of least privilege.
Implement Rerank 3 on Amazon SageMaker
To improve RAG performance using Cohere Rerank, use the instructions in the following sections.
Subscribe to the model package
To subscribe to the model package, follow these steps:
- In AWS Marketplace, open the model package listing page Cohere Rerank 3 Model – Multilingual
- Choose Continue to Subscribe.
- On the Subscribe to this software page, review the End User License Agreement (EULA), pricing, and support terms and choose Accept Offer.
- Choose Continue to configuration and then choose a Region. You will see a Product ARN displayed, as shown in the following screenshot. This is the model package Amazon Resource Name (ARN) that you need to specify while creating a deployable model using Boto3. Copy the ARN corresponding to your Region and enter it in the following cell.
The code snippets included in this post are sourced from the aws-cohere notebook. If you encounter any issues with this code, refer to the notebook for the most up-to-date version.
!pip install --upgrade cohere-aws
# if you upgrade the package, you need to restart the kernel
from cohere_aws import Client
import boto3On the Configure for AWS CloudFormation page shown in the following screenshot, under Product Arn, make a note of the last part of the product ARN to use as the value in the variable cohere_package in the following code.
cohere_package = " cohere-rerank-multilingual-v3--13dba038aab73b11b3f0b17fbdb48ea0"
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:865070037744:model-package/{cohere_package}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{cohere_package}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{cohere_package}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{cohere_package}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{cohere_package}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{cohere_package}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{cohere_package}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{cohere_package}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{cohere_package}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{cohere_package}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{cohere_package}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{cohere_package}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{cohere_package}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{cohere_package}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{cohere_package}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{cohere_package}",
}
region = boto3.Session().region_name
if region not in model_package_map.keys():
raise Exception(f"Current boto3 session region {region} is not supported.")
model_package_arn = model_package_map[region]Create an endpoint and perform real-time inference
If you want to understand how real-time inference with Amazon SageMaker works, refer to the Amazon SageMaker Developer Guide.
Create an endpoint
To create an endpoint, use the following code.
co = Client(region_name=region)
co.create_endpoint(arn=model_package_arn, endpoint_name="cohere-rerank-multilingual-v3-0", instance_type="ml.g5.2xlarge", n_instances=1)
# If the endpoint is already created, you just need to connect to it
# co.connect_to_endpoint(endpoint_name="cohere-rerank-multilingual-v3-0”)After the endpoint is created, you can perform real-time inference.
Create the input payload
To create the input payload, use the following code.
documents = [
{"Title":"Contraseña incorrecta","Content":"Hola, llevo una hora intentando acceder a mi cuenta y sigue diciendo que mi contraseña es incorrecta. ¿Puede ayudarme, por favor?"},
{"Title":"Confirmation Email Missed","Content":"Hi, I recently purchased a product from your website but I never received a confirmation email. Can you please look into this for me?"},
{"Title":"أسئلة حول سياسة الإرجاع","Content":"مرحبًا، لدي سؤال حول سياسة إرجاع هذا المنتج. لقد اشتريته قبل بضعة أسابيع وهو معيب"},
{"Title":"Customer Support is Busy","Content":"Good morning, I have been trying to reach your customer support team for the past week but I keep getting a busy signal. Can you please help me?"},
{"Title":"Falschen Artikel erhalten","Content":"Hallo, ich habe eine Frage zu meiner letzten Bestellung. Ich habe den falschen Artikel erhalten und muss ihn zurückschicken."},
{"Title":"Customer Service is Unavailable","Content":"Hello, I have been trying to reach your customer support team for the past hour but I keep getting a busy signal. Can you please help me?"},
{"Title":"Return Policy for Defective Product","Content":"Hi, I have a question about the return policy for this product. I purchased it a few weeks ago and it is defective."},
{"Title":"收到错误物品","Content":"早上好,关于我最近的订单,我有一个问题。我收到了错误的商品,需要退货。"},
{"Title":"Return Defective Product","Content":"Hello, I have a question about the return policy for this product. I purchased it a few weeks ago and it is defective."}
]
Perform real-time inference
To perform real-time inference, use the following code.response = co.rerank(documents=documents, query='What emails have been about returning items?', rank_fields=["Title","Content"], top_n=5)Visualize output
To visualize output, use the following code.
print(f'Documents: {response}')The following screenshot shows the output response.

Cleanup
To avoid any recurring charges, use the following steps to clean up the resources created in this walkthrough.
Delete the model
Now that you have successfully performed a real-time inference, you do not need the endpoint anymore. You can terminate the endpoint to avoid being charged.
co.delete_endpoint()
co.close()
Unsubscribe to the listing (optional)
If you want to unsubscribe to the model package, follow these steps. Before you cancel the subscription, make sure that you don’t have a deployable model created from the model package or using the algorithm. You can find this information by looking at the container name associated with the model.
Steps to unsubscribe from the product from AWS Marketplace:
- On the Your Software subscriptions page, choose the Machine Learning tab
- Locate the listing that you want to cancel the subscription for, and then choose Cancel Subscription
Summary
RAG is a capable technique for developing AI applications that integrate real-time data and enable interactive conversations using proprietary information. RAG enhances AI responses by tapping into external, domain-specific knowledge sources, but its effectiveness depends on finding the right source materials. This post focuses on improving search efficiency and accuracy in RAG systems using Cohere Rerank. RAG orchestration typically involves two steps: retrieval of relevant documents and generation of answers. While dense retrieval is efficient for large datasets, it can struggle with complex data and questions due to information compression. Cohere Rerank uses deep learning to evaluate the alignment between documents and queries, outputting a relevance score that enables more nuanced document selection.
Customers can find Cohere Rerank 3 and Cohere Rerank 3 Nimble on Amazon Sagemaker Jumpstart.
About the Authors
 Shashi Raina is a Senior Partner Solutions Architect at Amazon Web Services (AWS), where he specializes in supporting generative AI (GenAI) startups. With close to 6 years of experience at AWS, Shashi has developed deep expertise across a range of domains, including DevOps, analytics, and generative AI.
Shashi Raina is a Senior Partner Solutions Architect at Amazon Web Services (AWS), where he specializes in supporting generative AI (GenAI) startups. With close to 6 years of experience at AWS, Shashi has developed deep expertise across a range of domains, including DevOps, analytics, and generative AI.
 Pradeep Prabhakaran is a Senior Manager – Solutions Architecture at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform.
Pradeep Prabhakaran is a Senior Manager – Solutions Architecture at Cohere. In his current role at Cohere, Pradeep acts as a trusted technical advisor to customers and partners, providing guidance and strategies to help them realize the full potential of Cohere’s cutting-edge Generative AI platform.