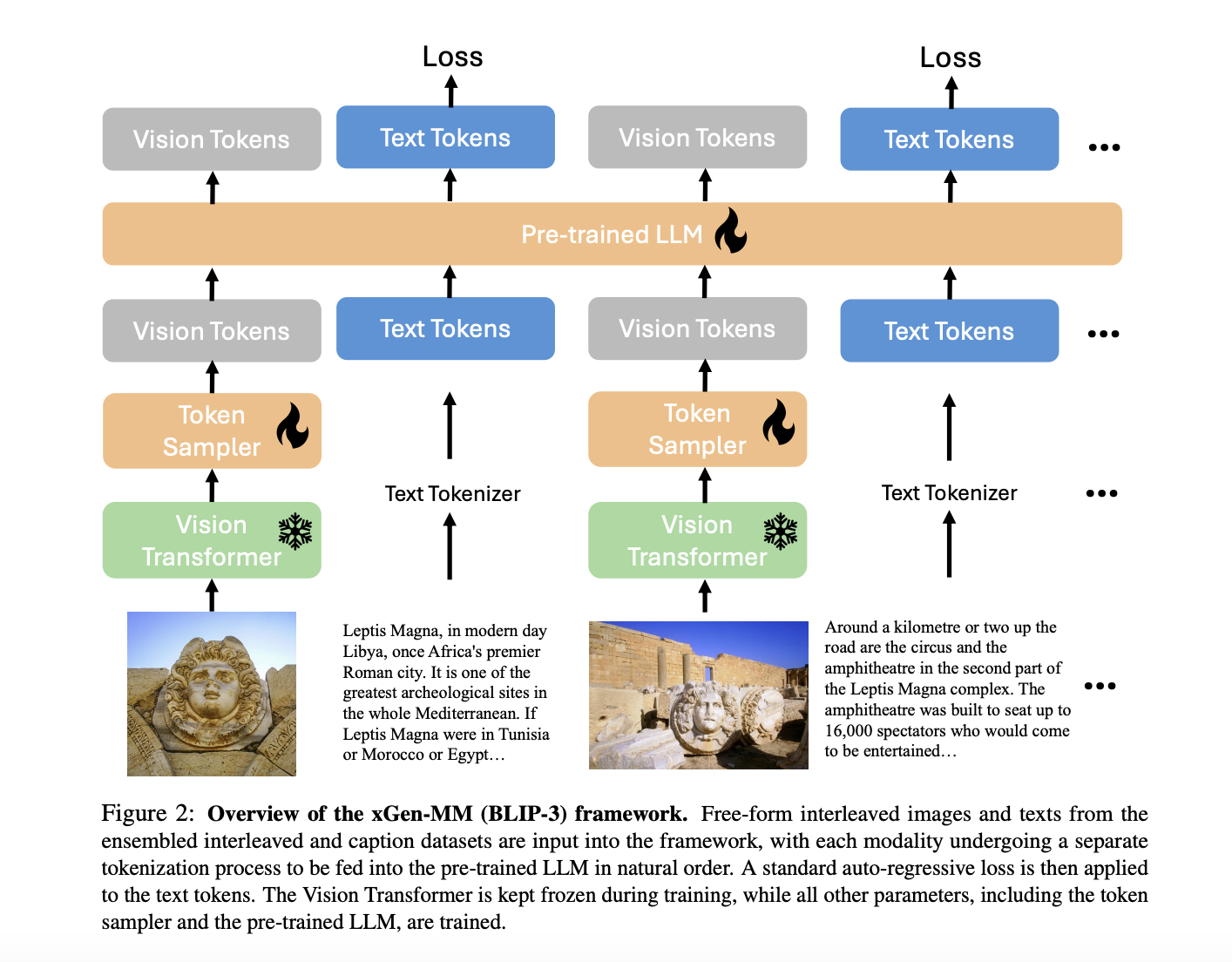
New benchmark for evaluating multimodal systems based on real-world video, audio, and text data
From the Turing test to ImageNet, benchmarks have played an instrumental role in shaping artificial intelligence (AI) by helping define research goals and allowing researchers to measure progress towards those goals. Incredible breakthroughs in the past 10 years, such as AlexNet in computer vision and AlphaFold in protein folding, have been closely linked to using benchmark datasets, allowing researchers to rank model design and training choices, and iterate to improve their models. As we work towards the goal of building artificial general intelligence (AGI), developing robust and effective benchmarks that expand AI models’ capabilities is as important as developing the models themselves.
Perception – the process of experiencing the world through senses – is a significant part of intelligence. And building agents with human-level perceptual understanding of the world is a central but challenging task, which is becoming increasingly important in robotics, self-driving cars, personal assistants, medical imaging, and more. So today, we’re introducing the Perception Test, a multimodal benchmark using real-world videos to help evaluate the perception capabilities of a model.
Developing a perception benchmark
Many perception-related benchmarks are currently being used across AI research, like Kinetics for video action recognition, Audioset for audio event classification, MOT for object tracking, or VQA for image question-answering. These benchmarks have led to amazing progress in how AI model architectures and training methods are built and developed, but each one only targets restricted aspects of perception: image benchmarks exclude temporal aspects; visual question-answering tends to focus on high-level semantic scene understanding; object tracking tasks generally capture lower-level appearance of individual objects, like colour or texture. And very few benchmarks define tasks over both audio and visual modalities.
Multimodal models, such as Perceiver, Flamingo, or BEiT-3, aim to be more general models of perception. But their evaluations were based on multiple specialised datasets because no dedicated benchmark was available. This process is slow, expensive, and provides incomplete coverage of general perception abilities like memory, making it difficult for researchers to compare methods.
To address many of these issues, we created a dataset of purposefully designed videos of real-world activities, labelled according to six different types of tasks:
- Object tracking: a box is provided around an object early in the video, the model must return a full track throughout the whole video (including through occlusions).
- Point tracking: a point is selected early on in the video, the model must track the point throughout the video (also through occlusions).
- Temporal action localisation: the model must temporally localise and classify a predefined set of actions.
- Temporal sound localisation: the model must temporally localise and classify a predefined set of sounds.
- Multiple-choice video question-answering: textual questions about the video, each with three choices from which to select the answer.
- Grounded video question-answering: textual questions about the video, the model needs to return one or more object tracks.
We took inspiration from the way children’s perception is assessed in developmental psychology, as well as from synthetic datasets like CATER and CLEVRER, and designed 37 video scripts, each with different variations to ensure a balanced dataset. Each variation was filmed by at least a dozen crowd-sourced participants (similar to previous work on Charades and Something-Something), with a total of more than 100 participants, resulting in 11,609 videos, averaging 23 seconds long.
The videos show simple games or daily activities, which would allow us to define tasks that require the following skills to solve:
- Knowledge of semantics: testing aspects like task completion, recognition of objects, actions, or sounds.
- Understanding of physics: collisions, motion, occlusions, spatial relations.
- Temporal reasoning or memory: temporal ordering of events, counting over time, detecting changes in a scene.
- Abstraction abilities: shape matching, same/different notions, pattern detection.
Crowd-sourced participants labelled the videos with spatial and temporal annotations (object bounding box tracks, point tracks, action segments, sound segments). Our research team designed the questions per script type for the multiple-choice and grounded video-question answering tasks to ensure good diversity of skills tested, for example, questions that probe the ability to reason counterfactually or to provide explanations for a given situation. The corresponding answers for each video were again provided by crowd-sourced participants.
Evaluating multimodal systems with the Perception Test
We assume that models have been pre-trained on external datasets and tasks. The Perception Test includes a small fine-tuning set (20{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09}) that the model creators can optionally use to convey the nature of the tasks to the models. The remaining data (80{29fe85292aceb8cf4c6c5bf484e3bcf0e26120073821381a5855b08e43d3ac09}) consists of a public validation split and a held-out test split where performance can only be evaluated via our evaluation server.
Here we show a diagram of the evaluation setup: the inputs are a video and audio sequence, plus a task specification. The task can be in high-level text form for visual question answering or low-level input, like the coordinates of an object’s bounding box for the object tracking task.
The evaluation results are detailed across several dimensions, and we measure abilities across the six computational tasks. For the visual question-answering tasks we also provide a mapping of questions across types of situations shown in the videos and types of reasoning required to answer the questions for a more detailed analysis (see our paper for more details). An ideal model would maximise the scores across all radar plots and all dimensions. This is a detailed assessment of the skills of a model, allowing us to narrow down areas of improvement.

Ensuring diversity of participants and scenes shown in the videos was a critical consideration when developing the benchmark. To do this, we selected participants from different countries of different ethnicities and genders and aimed to have diverse representation within each type of video script.

Learning more about the Perception Test
The Perception Test benchmark is publicly available here and further details are available in our paper. A leaderboard and a challenge server will be available soon too.
On 23 October, 2022, we’re hosting a workshop about general perception models at the European Conference on Computer Vision in Tel Aviv (ECCV 2022), where we will discuss our approach, and how to design and evaluate general perception models with other leading experts in the field.
We hope that the Perception Test will inspire and guide further research towards general perception models. Going forward, we hope to collaborate with the multimodal research community to introduce additional annotations, tasks, metrics, or even new languages to the benchmark.
Get in touch by emailing perception-test@google.com if you’re interested in contributing!