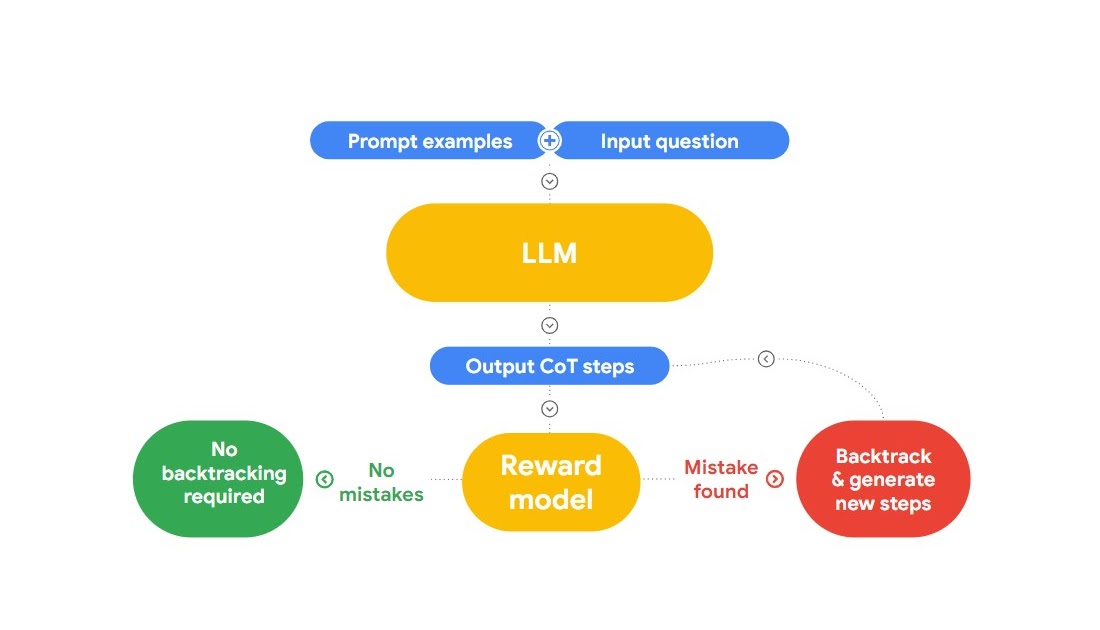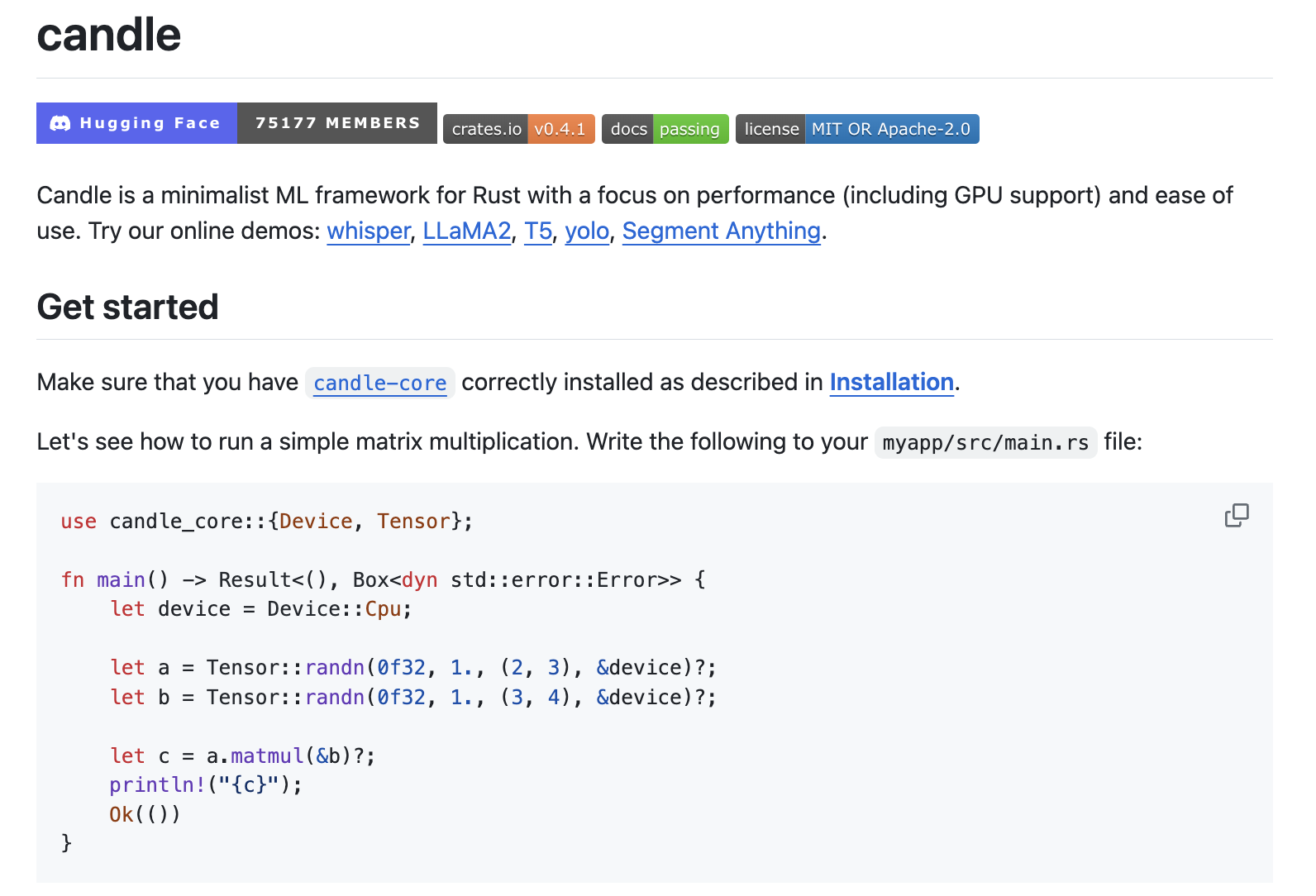
Deploying machine learning models efficiently is crucial for various applications. However, traditional frameworks like PyTorch come with their own set of challenges. They are large, making instance creation on a cluster slow, and their reliance on Python can cause performance issues due to overhead and the Global Interpreter Lock (GIL). As a result, there is a need for a more lightweight and efficient solution.
Existing solutions such as dfdx and tch-rs offer alternatives, but they each have their limitations. While dfdx provides shape inclusion in types to prevent shape mismatches, it may still require nightly features and can be challenging for non-Rust experts. On the other hand, tch-rs offers versatile bindings to the torch library in Rust but brings in the entire torch library into the runtime, which may not be optimal for all scenarios.
Meet Candle, a minimalist Machine Learning ML framework for Rust that addresses these challenges. Candle prioritizes performance, including GPU support and ease of use, with a syntax resembling PyTorch. Its core goal is to enable serverless inference by facilitating the deployment of lightweight binaries. By leveraging Rust, Candle eliminates Python overhead and the GIL, thus enhancing performance and reliability.
Candle offers various features to support its goals. It provides model training capabilities, backends including optimized CPU and CUDA support for GPUs, and even WASM support for running models in web browsers. Moreover, Candle includes a range of pre-trained models across different domains, from language models to computer vision and audio processing.
Candle achieves fast inference times with its optimized CPU backend, making it suitable for real-time applications. Its CUDA backend allows for efficient utilization of GPUs, enabling high-throughput processing of large datasets. Additionally, Candle’s support for WASM facilitates lightweight deployment in web environments, extending its reach to a broader range of applications.
In summary, Candle presents a compelling solution to the challenges of deploying machine learning models efficiently. By leveraging the performance advantages of Rust and a minimalist design that prioritizes ease of use, Candle empowers developers to streamline their workflows and achieve optimal performance in production environments.
Try some online demos: whisper, LLaMA2, T5, yolo, Segment Anything.
Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.