In machine learning and artificial intelligence, training large language models (LLMs) like those used for understanding and generating human-like text is time-consuming and resource-intensive. The speed at which these models learn from data and improve their abilities directly impacts how quickly new and more advanced AI applications can be developed and deployed. The challenge is finding ways to make this training process faster and more efficient, allowing quicker iterations and innovations.
The existing solution to this problem has been the development of optimized software libraries and tools designed specifically for deep learning tasks. Researchers and developers widely use these tools, such as PyTorch, for their flexibility and ease of use. PyTorch, in particular, offers a dynamic computation graph that allows for intuitive model building and debugging. However, even with these advanced tools, the demand for faster computation and more efficient use of hardware resources continues growing, especially as models become more complex.
Meet Thunder: a new compiler designed to work alongside PyTorch. Enhancing its performance without requiring users to abandon the familiar PyTorch environment. The compiler achieves this by optimizing the execution of deep learning models, making the training process significantly faster. What sets Thunder apart is its ability to be used in conjunction with PyTorch’s optimization tools, such as `PyTorch.compile`, to achieve even more significant speedups.
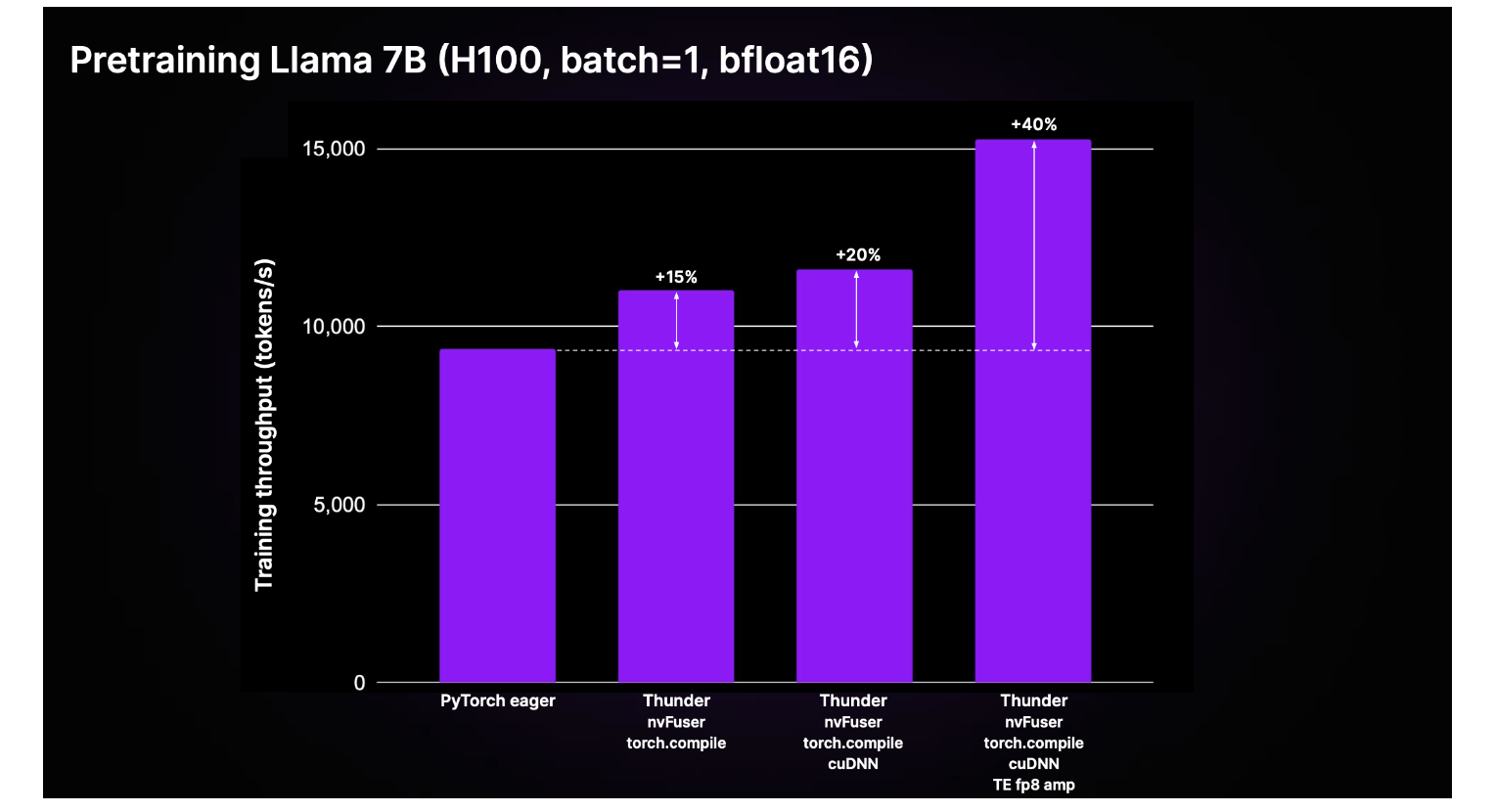
Thunder has shown impressive results. Specifically, training tasks for large language models, such as a 7-billion parameter LLM, can achieve a 40% speedup compared to regular PyTorch. This improvement is not limited to single-GPU setups but extends to multi-GPU training environments, supported by distributed data-parallel (DDP) and fully sharded data-parallel (FSDP) techniques. Moreover, Thunder is designed to be user-friendly, allowing easy integration into existing projects with minimal code changes, for instance, by simply wrapping a PyTorch model with the `Thunder. Jit ()` function, users can leverage the compiler’s optimizations.
Thunder’s seamless integration with PyTorch and notable speed improvements make it a valuable tool. By reducing the time and resources needed for model training, Thunder opens up new possibilities for innovation and exploration in AI. As more users try out Thunder and provide feedback, its capabilities are expected to evolve, further enhancing the efficiency of AI model development.

Niharika is a Technical consulting intern at Marktechpost. She is a third year undergraduate, currently pursuing her B.Tech from Indian Institute of Technology(IIT), Kharagpur. She is a highly enthusiastic individual with a keen interest in Machine learning, Data science and AI and an avid reader of the latest developments in these fields.