Large open-source pre-training datasets are important for the research community in exploring data engineering and developing transparent, open-source models. However, there’s a major shift from frontier labs to training large multimodal models (LMMs) that need large datasets containing both images and texts. The capabilities of these frontier models are advancing quickly, creating a large gap between the multimodal training data available for closed and open-source models. Current open-source multimodal datasets are smaller and less diverse compared to text-only datasets, making it challenging to develop strong open-source LMMs and widening the gap in performance between open and closed-source models.
Some of the related works discussed in this paper are Multimodal Interleaved Data, Large Open-source Pre-training Datasets, and LMMs. Multimodal interleaved datasets were first presented in Flamingo and CM3. The first open-source versions of these datasets were Multimodal-C4 and OBELICS. Recent works like Chameleon and MM1 have scaled OBELICS to train state-of-the-art multimodal models. The second approach is the backbone of open-source research and is important for training strong open-source multimodal models. In LMMs, researchers aim to pre-train language models using large-scale multimodal interleaved and image-text datasets. This was introduced by Flamingo and adopted by open-source models like OpenFlamingo, Idefics, and Emu.
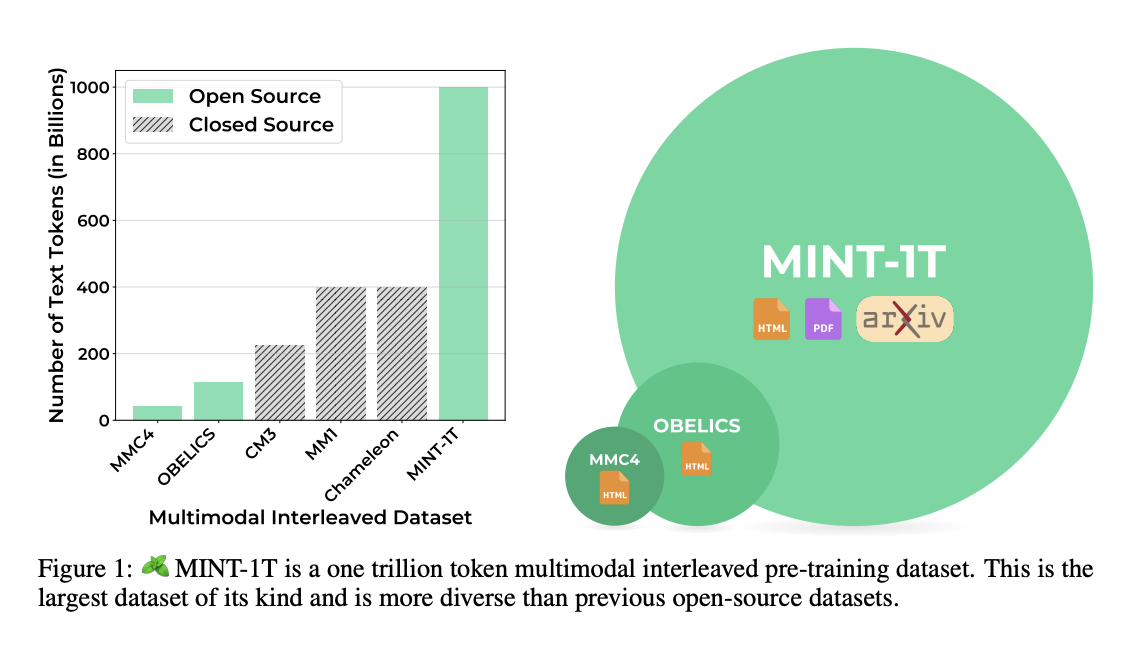
Researchers from the University of Washington, Salesforce Research, Stanford University, the University of Texas at Austin, and the University of California, Berkeley have proposed Multimodal INTerleaved (MINT-1T). Currently, MINT-1T is the largest and most diverse open-source multimodal interleaved dataset, which contains one trillion text tokens and three billion images, collected from various sources such as HTML, PDFs, and ArXiv. LLMs trained on MINT-1T offer 10 times improvement in scale and potentially it outperform models trained on the best existing open-source dataset, OBELICS which contains a 115 billion text token dataset with 353M images sourced only from HTML.
MINT-1T has created a large open-source dataset by collecting diverse sources of mixed documents, including PDFs and ArXiv papers, and the final dataset contains 965B HTML document tokens, 51B PDF tokens, and 10B ArXiv tokens. For filtering text quality, not using model-based heuristics helps in the efficient scaling of tex-only models. This includes eliminating non-English documents using Fasttext’s language identification model with a confidence threshold of 0.65. Further, documents containing URLs with NSFW substrings are removed to avoid pornographic and undesirable content, and text filtering methods from RefinedWeb are applied to remove documents with excessive duplicate n-grams.
To enhance the performance of In-Context Learning, models are prompted with 1 to 15 examples and executed a single trial per shot count for each evaluation benchmark. The results show that the model trained on MINT-1T performs better than the model trained on the HTML subset of MINT-1T for all shots. Further, MINT-1T models perform similarly to the OBELICS from 1 to 10 but outperform after 10 shots. When evaluating performance on MMMU for each domain, MINT-1T outperforms OBELICS and HTML baseline of MINT-1T, except in the Business domain. The method shows enhanced performance in Science and Technology domains due to the high representation of these domains in ArXiv and PDF documents.
In this paper, researchers have introduced MINT-1T, the first open-source trillion token multimodal interleaved dataset and an important component for training large multimodal models. This method is an important resource for the research community to do open science on multimodal interleaved datasets. MINT-1T outperforms the previous largest open-source dataset in this domain, OBELICS that contains a 115 billion text token dataset with 353M images sourced only from HTML. Future work includes training models on larger subsets of MINT-1T, and developing multimodal document filtering methods to enhance data quality.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter.
Join our Telegram Channel and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 44k+ ML SubReddit

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.