Large Language Models (LMMs) are developing significantly and proving to be capable of handling more complicated jobs that call for a blend of different integrated skills. Among these jobs include GUI navigation, converting images to code, and comprehending films. A number of benchmarks, including MME, MMBench, SEEDBench, MMMU, and MM-Vet, have been established in order to comprehensively evaluate the performance of LMMs. It concentrates on assessing LMMs according to their capacity to integrate fundamental functions.
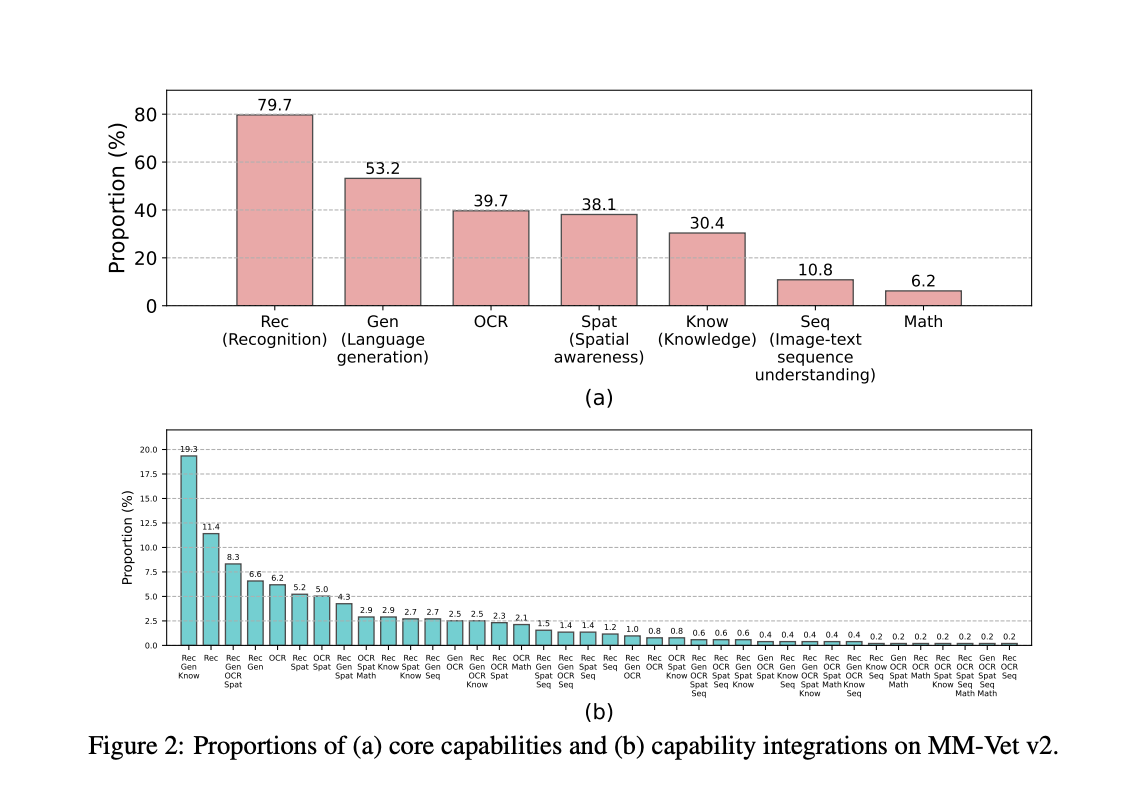
In recent research, MM-Vet has established itself as one of the most popular benchmarks for evaluating LLMs, particularly through its use of open-ended vision-language questions designed to assess integrated capabilities. Six fundamental vision-language (VL) skills are particularly assessed by this benchmark: numeracy, recognition, knowledge, spatial awareness, language creation, and optical character recognition (OCR). Many real-world applications depend on the ability to comprehend and absorb written and visual information cohesively, which is made possible by these skills.
However, there’s limitation with the original MM-Vet format: it can only be used for questions with a single image-text pair. This is problematic because it fails to capture the intricacy of real-world situations, where information is frequently presented in text and visual sequences. In these kinds of situations, a model is put to the test in a more sophisticated and practical way by having to comprehend and interpret a variety of textual and visual information in context.
MM-Vet has been improved to MM-Vet v2 in order to get around this restriction. ‘Image-text sequence understanding’ is the seventh VL capability included in this edition. This feature is intended to assess a model’s processing speed for sequences containing both text and visual information, more representative of the kinds of tasks that Large Multimodal Models (LMMs) are likely to encounter in real-world scenarios. With the addition of this new feature, MM-Vet v2 offers a more thorough evaluation of an LMM’s overall effectiveness and capacity to manage intricate and interconnected tasks.
MM-Vet v2 aims to increase the size of the evaluation set while preserving the high caliber of the assessment samples, in addition to improving the capabilities evaluated. This guarantees that the standard will continue to be strict and trustworthy even as it expands to encompass increasingly difficult and varied jobs. After benchmarking multiple LMMs using MM-Vet v2, it was shown that Claude 3.5 Sonnet has the greatest performance score (71.8). This marginally outperformed GPT-4o, which had a score of 71.0, suggesting that Claude 3.5 Sonnet is marginally more adept at completing the challenging tasks assessed by MM-Vet v2. With a competitive score of 68.4, InternVL2-Llama3-76B stood out as the top open-weight model, proving its robustness in spite of its open-weight status.
In conclusion, MM-Vet v2 is a major step forward in the evaluation of LMMs. It provides a more comprehensive and realistic assessment of their abilities by adding the capacity to comprehend and process image-text sequences, as well as increasing the evaluation set’s quality and scope.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.