Large language models (LLMs) are very large deep-learning models that are pre-trained on vast amounts of data. LLMs are incredibly flexible. One model can perform completely different tasks such as answering questions, summarizing documents, translating languages, and completing sentences. LLMs have the potential to revolutionize content creation and the way people use search engines and virtual assistants. Retrieval Augmented Generation (RAG) is the process of optimizing the output of an LLM, so it references an authoritative knowledge base outside of its training data sources before generating a response. While LLMs are trained on vast volumes of data and use billions of parameters to generate original output, RAG extends the already powerful capabilities of LLMs to specific domains or an organization’s internal knowledge base—without having to retrain the LLMs. RAG is a fast and cost-effective approach to improve LLM output so that it remains relevant, accurate, and useful in a specific context. RAG introduces an information retrieval component that uses the user input to first pull information from a new data source. This new data from outside of the LLM’s original training data set is called external data. The data might exist in various formats such as files, database records, or long-form text. An AI technique called embedding language models converts this external data into numerical representations and stores it in a vector database. This process creates a knowledge library that generative AI models can understand.
RAG introduces additional data engineering requirements:
- Scalable retrieval indexes must ingest massive text corpora covering requisite knowledge domains.
- Data must be preprocessed to enable semantic search during inference. This includes normalization, vectorization, and index optimization.
- These indexes continuously accumulate documents. Data pipelines must seamlessly integrate new data at scale.
- Diverse data amplifies the need for customizable cleaning and transformation logic to handle the quirks of different sources.
In this post, we will explore building a reusable RAG data pipeline on LangChain—an open source framework for building applications based on LLMs—and integrating it with AWS Glue and Amazon OpenSearch Serverless. The end solution is a reference architecture for scalable RAG indexing and deployment. We provide sample notebooks covering ingestion, transformation, vectorization, and index management, enabling teams to consume disparate data into high-performing RAG applications.
Data preprocessing for RAG
Data pre-processing is crucial for responsible retrieval from your external data with RAG. Clean, high-quality data leads to more accurate results with RAG, while privacy and ethics considerations necessitate careful data filtering. This lays the foundation for LLMs with RAG to reach their full potential in downstream applications.
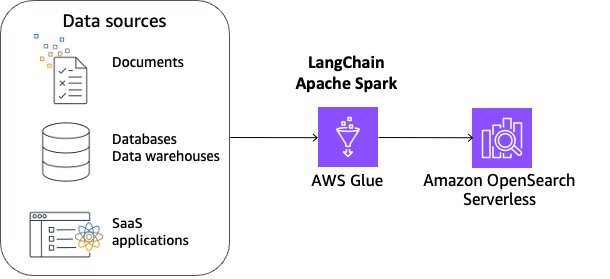
To facilitate effective retrieval from external data, a common practice is to first clean up and sanitize the documents. You can use Amazon Comprehend or AWS Glue sensitive data detection capability to identify sensitive data and then use Spark to clean up and sanitize the data. The next step is to split the documents into manageable chunks. The chunks are then converted to embeddings and written to a vector index, while maintaining a mapping to the original document. This process is shown in the figure that follows. These embeddings are used to determine semantic similarity between queries and text from the data sources
Solution overview
In this solution, we use LangChain integrated with AWS Glue for Apache Spark and Amazon OpenSearch Serverless. To make this solution scalable and customizable, we use Apache Spark’s distributed capabilities and PySpark’s flexible scripting capabilities. We use OpenSearch Serverless as a sample vector store and use the Llama 3.1 model.

The benefits of this solution are:
- You can flexibly achieve data cleaning, sanitizing, and data quality management in addition to chunking and embedding.
- You can build and manage an incremental data pipeline to update embeddings on Vectorstore at scale.
- You can choose a wide variety of embedding models.
- You can choose a wide variety of data sources including databases, data warehouses, and SaaS applications supported in AWS Glue.
This solution covers the following areas:
- Processing unstructured data such as HTML, Markdown, and text files using Apache Spark. This includes distributed data cleaning, sanitizing, chunking, and embedding vectors for downstream consumption.
- Bringing it all together into a Spark pipeline that incrementally processes sources and publishes vectors to an OpenSearch Serverless
- Querying the indexed content using the LLM model of your choice to provide natural language answers.
Prerequisites
To continue this tutorial, you must create the following AWS resources in advance:
- An Amazon Simple Storage Service (Amazon S3) bucket for storing data
- An AWS Identity and Access Management (IAM) role for your AWS Glue notebook as instructed in Set up IAM permissions for AWS Glue Studio. It requires IAM permission for OpenSearch Service Serverless. Here’s an example policy:
Complete the following steps to launch an AWS Glue Studio notebook:
- Download the Jupyter Notebook file.
- On the AWS Glue console, chooseNotebooks in the navigation pane.
- Under Create job, select Notebook.
- For Options, choose Upload Notebook.
- Choose Create notebook. The notebook will start up in a minute.

- Run the first two cells to configure an AWS Glue interactive session.

Now you have configured the required settings for your AWS Glue notebook.
Vector store setup
First, create a vector store. A vector store provides efficient vector similarity search by providing specialized indexes. RAG complements LLMs with an external knowledge base that’s typically built using a vector database hydrated with vector-encoded knowledge articles.
In this example, you will use Amazon OpenSearch Serverless for its simplicity and scalability to support a vector search at low latency and up to billions of vectors. Learn more in Amazon OpenSearch Service’s vector database capabilities explained.
Complete the following steps to set up OpenSearch Serverless:
- For the cell under Vectorestore Setup, replace <your-iam-role-arn> with your IAM role Amazon Resource Name (ARN), replace <region> with your AWS Region, and run the cell.
- Run the next cell to create the OpenSearch Serverless collection, security policies, and access policies.

You have provisioned OpenSearch Serverless successfully. Now you’re ready to inject documents into the vector store.
Document preparation
In this example, you will use a sample HTML file as the HTML input. It’s an article with specialized content that LLMs cannot answer without using RAG.
- Run the cell under Sample document download to download the HTML file, create a new S3 bucket, and upload the HTML file to the bucket.

- Run the cell under Document preparation. It loads the HTML file into Spark DataFrame df_html.

- Run the two cells under Parse and clean up HTMLto define functions
parse_htmlandformat_md. We use Beautiful Soup to parse HTML, and convert it to Markdown using markdownify in order to use MarkdownTextSplitter for chunking. These functions will be used inside a Spark Python user-defined function (UDF) in later cells.

- Run the cell under Chunking HTML. The example uses LangChain’s
MarkdownTextSplitterto split the text along markdown-formatted headings into manageable chunks. Adjusting chunk size and overlap is crucial to help prevent the interruption of contextual meaning, which can affect the accuracy of subsequent vector store searches. The example uses a chunk size of 1,000 and a chunk overlap of 100 to preserve information continuity, but these settings can be fine-tuned to suit different use cases.

- Run the three cells under Embedding. The first two cells configure LLMs and deploy them through Amazon SageMaker In the third cell, the function
process_batchinjectsthe documents into the vector store through OpenSearch implementation inside LangChain, which inputs the embeddings model and the documents to create the entire vector store.



- Run the two cells under Pre-process HTML document. The first cell defines the Spark UDF, and the second cell triggers the Spark action to run the UDF per record containing the entire HTML content.

You have successfully ingested an embedding into the OpenSearch Serverless collection.
Question answering
In this section, we are going to demonstrate the question-answering capability using the embedding ingested in the previous section.
- Run the two cells under Question Answering to create the
OpenSearchVectorSearchclient, the LLM using Llama 3.1, and define RetrievalQA where you can customize how the documents fetched should be added to the prompt using thechain_typeOptionally, you can choose other foundation models (FMs). For such cases, refer to the model card to adjust the chunking length.


- Run the next cell to do a similarity search using the query “What is Task Decomposition?” against the vector store providing the most relevant information. It takes a few seconds to make documents available in the index. If you get an empty output in the next cell, wait 1-3 minutes and retry.

Now that you have the relevant documents, it’s time to use the LLM to generate an answer based on the embeddings.
- Run the next cell to invoke the LLM to generate an answer based on the embeddings.

As you expect, the LLM answered with a detailed explanation about task decomposition. For production workloads, balancing latency and cost efficiency is crucial in semantic searches through vector stores. It’s important to select the most suitable k-NN algorithm and parameters for your specific needs, as detailed in this post. Additionally, consider using product quantization (PQ) to reduce the dimensionality of embeddings stored in the vector database. This approach can be advantageous for latency-sensitive tasks, though it might involve some trade-offs in accuracy. For additional details, see Choose the k-NN algorithm for your billion-scale use case with OpenSearch.
Clean up
Now to the final step, cleaning up the resources:
- Run the cell under Clean up to delete S3, OpenSearch Serverless, and SageMaker resources.

- Delete the AWS Glue notebook job.
Conclusion
This post explored a reusable RAG data pipeline using LangChain, AWS Glue, Apache Spark, Amazon SageMaker JumpStart, and Amazon OpenSearch Serverless. The solution provides a reference architecture for ingesting, transforming, vectorizing, and managing indexes for RAG at scale by using Apache Spark’s distributed capabilities and PySpark’s flexible scripting capabilities. This enables you to preprocess your external data in the phases including cleaning, sanitization, chunking documents, generating vector embeddings for each chunk, and loading into a vector store.
About the Authors
 Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
Noritaka Sekiyama is a Principal Big Data Architect on the AWS Glue team. He is responsible for building software artifacts to help customers. In his spare time, he enjoys cycling with his road bike.
 Akito Takeki is a Cloud Support Engineer at Amazon Web Services. He specializes in Amazon Bedrock and Amazon SageMaker. In his spare time, he enjoys travelling and spending time with his family.
Akito Takeki is a Cloud Support Engineer at Amazon Web Services. He specializes in Amazon Bedrock and Amazon SageMaker. In his spare time, he enjoys travelling and spending time with his family.
 Ray Wang is a Senior Solutions Architect at Amazon Web Services. Ray is dedicated to building modern solutions on the Cloud, especially in NoSQL, big data, and machine learning. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
Ray Wang is a Senior Solutions Architect at Amazon Web Services. Ray is dedicated to building modern solutions on the Cloud, especially in NoSQL, big data, and machine learning. As a hungry go-getter, he passed all 12 AWS certificates to make his technical field not only deep but wide. He loves to read and watch sci-fi movies in his spare time.
 Vishal Kajjam is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ Data Integration needs. In his spare time, he enjoys spending time with family and friends.
Vishal Kajjam is a Software Development Engineer on the AWS Glue team. He is passionate about distributed computing and using ML/AI for designing and building end-to-end solutions to address customers’ Data Integration needs. In his spare time, he enjoys spending time with family and friends.
 Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on generative AI applications for the Data Integration domain and distributed systems for efficiently managing data lakes on AWS and optimizing Apache Spark for performance and reliability.
Savio Dsouza is a Software Development Manager on the AWS Glue team. His team works on generative AI applications for the Data Integration domain and distributed systems for efficiently managing data lakes on AWS and optimizing Apache Spark for performance and reliability.
 Kinshuk Pahare is a Principal Product Manager on AWS Glue. He leads a team of Product Managers who focus on AWS Glue platform, developer experience, data processing engines, and generative AI. He had been with AWS for 4.5 years. Before that he did product management at Proofpoint and Cisco.
Kinshuk Pahare is a Principal Product Manager on AWS Glue. He leads a team of Product Managers who focus on AWS Glue platform, developer experience, data processing engines, and generative AI. He had been with AWS for 4.5 years. Before that he did product management at Proofpoint and Cisco.

