Large language models (LLMs) have evolved to become powerful tools capable of understanding and responding to user instructions. Based on the transformer architecture, these models predict the next word or token in a sentence, generating responses with remarkable fluency. However, they typically respond without engaging in internal thought processes that could help improve the accuracy of their answers, especially in more complex tasks. While methods like Chain-of-Thought (CoT) prompting have been developed to improve reasoning, these techniques have needed more success outside of logical and mathematical tasks. Researchers are now focusing on equipping LLMs to think before responding, enhancing their performance across various functions, including creative writing and general knowledge queries.
One of the main challenges with LLMs is their tendency to respond without considering the complexity of the instructions. For simple tasks, immediate responses may be sufficient, but these models often fall short for more intricate problems requiring logical reasoning or problem-solving. The difficulty lies in training models to pause, generate internal thoughts, and evaluate these thoughts before delivering a final response. This type of training is traditionally resource-intensive and requires large datasets of human-annotated thoughts, which are only sometimes available for some domains. As a result, the problem researchers face is how to create more intelligent LLMs that can apply reasoning across various tasks without relying on extensive human-labeled data.
Several approaches have been developed to address this issue and prompt LLMs to break down complex problems. Chain-of-thought (CoT) prompting is one such method where the model is asked to write out intermediate reasoning steps, allowing it to tackle tasks more structured. However, CoT methods have primarily been successful in fields such as mathematics and logic, where clear reasoning steps are required. In domains like marketing or creative writing, where answers are more subjective, CoT often fails to provide significant improvements. This limitation is compounded by the fact that the datasets used to train LLMs generally contain human responses rather than the internal thought processes behind those responses, making it difficult to refine the reasoning abilities of the models in diverse areas.
Researchers from Meta FAIR, the University of California, Berkeley, and New York University introduced a novel training method called Thought Preference Optimization (TPO). TPO aims to equip existing LLMs with the ability to generate and refine internal thoughts before producing a response. Unlike traditional methods that rely on human-labeled data, TPO requires no additional human annotation, making it a cost-effective solution. The TPO method begins by instructing the model to divide its output into two distinct parts: the thought process and the final response. Multiple thoughts are generated for each user instruction, and these thought-response pairs are evaluated through preference optimization. The best thought-response pairs are selected for further training iterations, gradually allowing the model to improve its reasoning capabilities.
At the core of TPO is a reinforcement learning (RL) technique that allows the model to learn from its thought generation. The model is prompted to generate thoughts before answering, and a judge model scores the resulting responses. By iterating on this process and optimizing the thoughts that lead to higher-quality responses, the model becomes better at understanding complex queries and delivering well-thought-out answers. This iterative approach is critical because it allows the model to refine its reasoning without requiring direct human intervention, making it a scalable solution for improving LLMs across various domains.
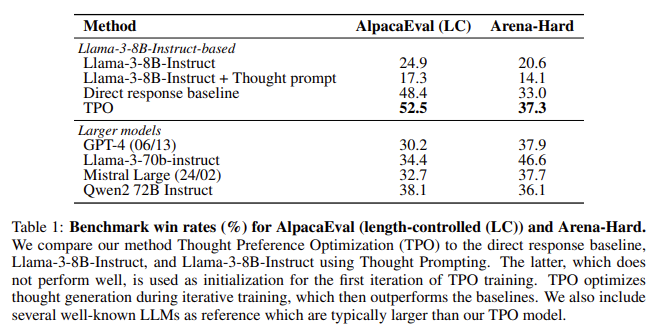
The effectiveness of TPO was tested on two prominent benchmarks: AlpacaEval and Arena-Hard. On AlpacaEval, the TPO model achieved a win rate of 52.5%, outperforming the direct response baseline by 4.1%. Similarly, it registered a win rate of 37.3% on Arena-Hard, outperforming traditional methods by 4.3%. These notable improvements demonstrate that TPO is effective in logic-based tasks and areas typically not associated with reasoning, such as marketing and health-related queries. The researchers observed that LLMs equipped with TPO showed gains even in creative writing and general knowledge tasks, indicating the broad applicability of the method.
One of the most significant findings of the research is that thinking-based models performed better than direct response models across various domains. Even in non-reasoning tasks like creative writing, TPO-enabled models could plan their responses more effectively, resulting in better outcomes. The iterative nature of TPO training also means that the model continues to improve with each iteration, as seen in the rising win rates across multiple benchmarks. For instance, after four iterations of TPO training, the model achieved a 52.5% win rate on AlpacaEval, a 27.6% increase from the initial seed model. The Arena-Hard benchmark saw similar trends, with the model matching and eventually surpassing the direct baseline after several iterations.
Key Takeaways from the Research:
- TPO increased the win rate of LLMs by 52.5% on AlpacaEval and 37.3% on Arena-Hard.
- The method eliminates the need for human-labeled data, making it cost-effective and scalable.
- TPO improved non-reasoning tasks such as marketing, creative writing, and health-related queries.
- After four iterations, TPO models achieved a 27.6% improvement over the initial seed model on AlpacaEval.
- The approach has broad applicability, extending beyond traditional reasoning tasks to general instruction following.

In conclusion, Thought Preference Optimization (TPO) allows models to think before responding. TPO addresses one of the key limitations of traditional LLMs: their inability to handle complex tasks that require logical reasoning or multi-step problem-solving. The research demonstrates that TPO can improve performance across various tasks, from logic-based problems to creative and subjective queries. TPO’s iterative, self-improving nature makes it a promising approach for future developments in LLMs, offering broader applications in fields beyond traditional reasoning tasks.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.