Recognition of human motion using time series from mobile and wearable devices is commonly used as key context information for various applications, from health condition monitoring to sports activity analysis to user habit studies. However, collecting large-scale motion time series data remains challenging due to security or privacy concerns. In the motion time series domain, the lack of datasets and an effective pre-training task makes it difficult to develop similar models that can operate with limited data. Typically, existing models perform training and testing on the same dataset, and they struggle to generalize across different datasets given three unique challenges within the motion time series problem domain: First, placing devices in different locations on the body—like on the wrist versus the leg—leads to very different data, which makes it tough to use a model trained for one spot on another part. Second, since devices can be held in various orientations, it’s problematic because models trained with a device in one position often struggle when the device is held differently. Lastly, different datasets often focus on different types of activities, making it hard to compare or combine the data effectively.
The conventional motion time series classification relies on separate classifiers for each dataset, using methods like statistical feature extraction, CNNs, RNNs, and attention models. General-purpose models like TimesNet and SHARE aim for task versatility, but they require training or testing on the same dataset; hence, they limit adaptability. Self-supervised learning helps in representation learning, though generalization across various datasets remains challenging. Pretrained models like ImageBind and IMU2CLIP consider motion and text data, but they are constrained by device-specific training. Methods that use large language models (LLMs) rely on prompts but have difficulty recognizing complex activities as they are not trained on raw motion time series and struggle with accurately recognizing complex activities.
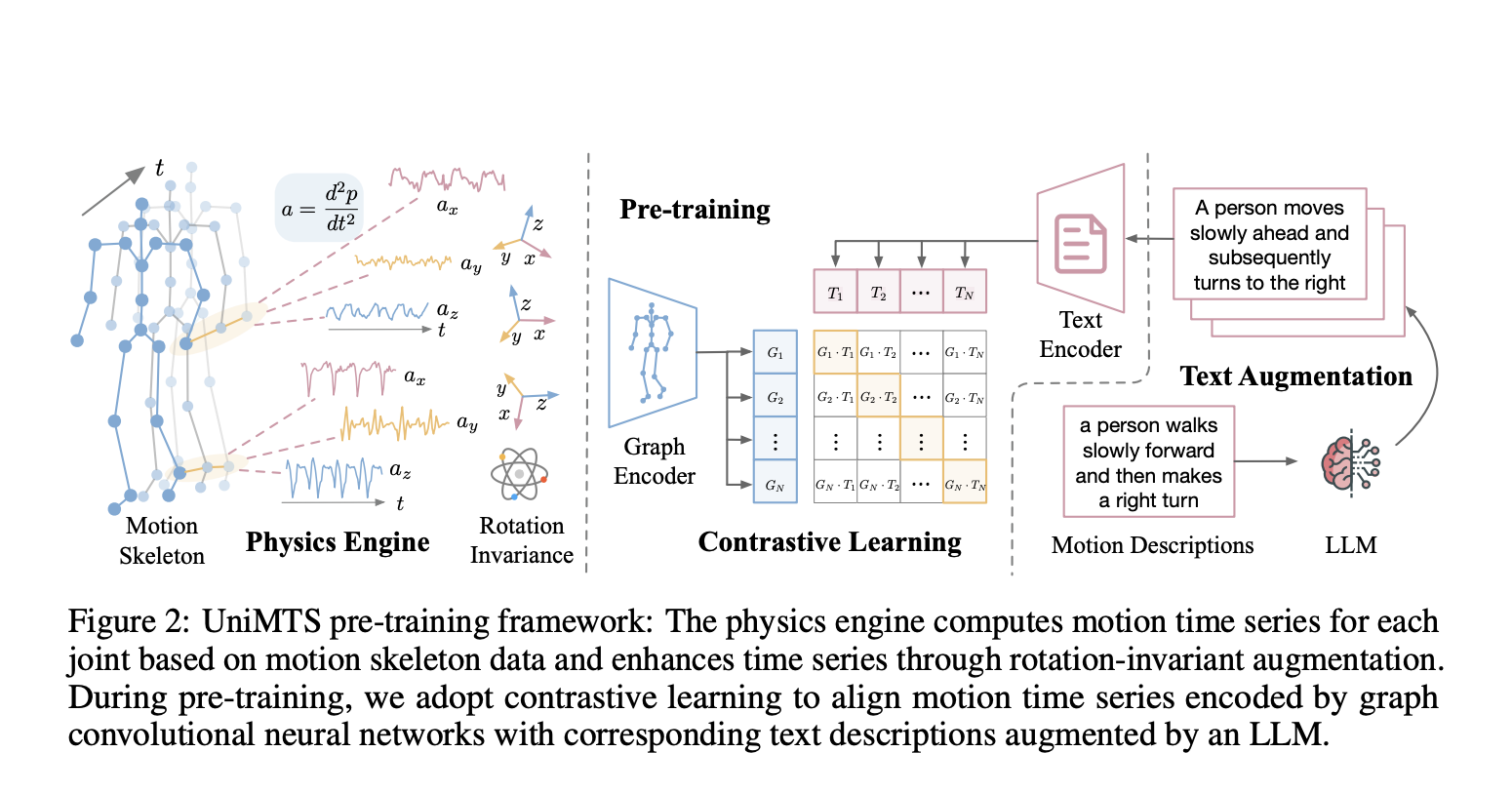
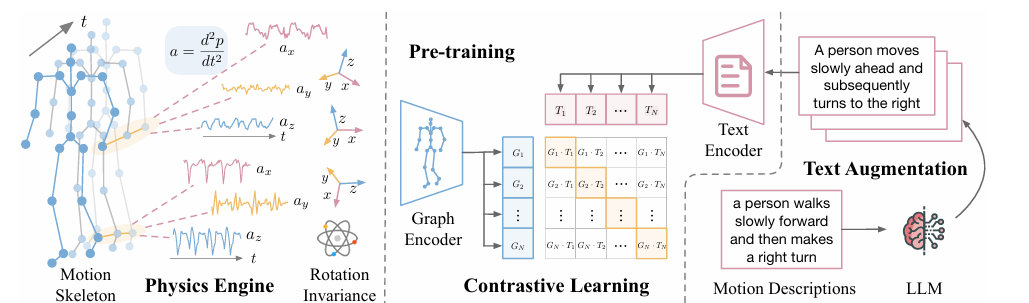
A group of researchers from UC San Diego, Amazon, and Qualcomm proposed UniMTS as the first unified pre-training procedure for motion time series that generalizes across diverse device latent factors and activities. UniMTS uses a contrastive learning framework to link motion time series data with enriched text descriptions from large language models (LLMs). This helps the model to understand the meaning behind different movements and allows it to generalize across various activities. For large-scale pre-training, UniMTS generates motion time series data based on existing detailed skeleton data, which covers various body parts. The generated data is then processed using graph networks to capture both spatial and temporal relationships across different device locations, helping the model generalize to data from different device placements.
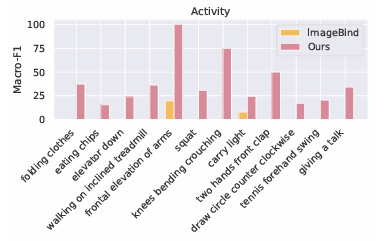
The process begins by creating motion data from skeleton movements and adjusting it according to different orientations. It also uses a graph encoder to understand how joints connect so it can work well across different devices. The text descriptions are improved using large language models. To create motion data, it calculates the velocities and accelerations of each joint while it considers their positions and orientations, adding noise to mimic real-world sensor errors. To handle inconsistencies in device orientation, UniMTS uses data augmentation to create random orientations during pre-training. This method takes into account variations in device positions and axis setups. By aligning motion data with text descriptions, the model can adapt well to different orientations and activity types. For training, UniMTS employs rotation-invariant data augmentation to handle device positioning differences. It was tested on the HumanML3D dataset and 18 other real-world motion time series benchmark datasets, notably with a performance improvement of 340% in the zero-shot setting, 16.3% in the few-shot setting, and 9.2% in the full-shot setting, compared with the respective best-performing baselines. The model’s performance was compared to baselines like ImageBind and IMU2CLIP. Results showed UniMTS outperformed other models, notably in zero-shot settings, based on statistical tests that confirmed significant improvements.
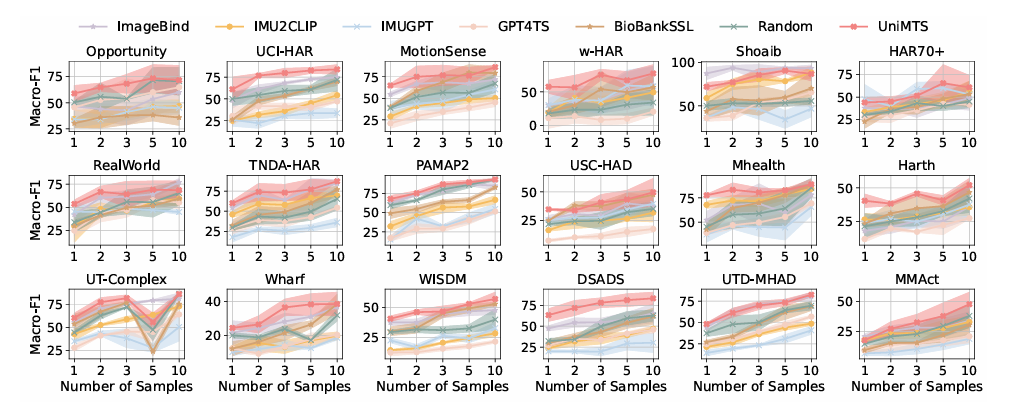
In conclusion, the proposed pre-trained model UniMTS is solely based on physics-simulated data, yet it shows remarkable generalization across diverse real-world motion time series datasets featuring different device locations, orientations, and activities. While leveraging its performance from traditional methods, UniMTS possesses some limitations, too. In a broader sense, this pre-trained motion time series classification model can act as a potential base for the upcoming research in the field of human motion recognition!
Check out the Paper, GitHub, and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Research/Product/Webinar with 1Million+ Monthly Readers and 500k+ Community Members
Divyesh is a consulting intern at Marktechpost. He is pursuing a BTech in Agricultural and Food Engineering from the Indian Institute of Technology, Kharagpur. He is a Data Science and Machine learning enthusiast who wants to integrate these leading technologies into the agricultural domain and solve challenges.