In the evolving landscape of artificial intelligence, the study of how machines understand and process human language has unveiled intriguing insights, particularly within large language models (LLMs). These digital marvels, designed to predict subsequent words or generate text, embody a realm of complexity that belies the underlying simplicity in their approach to language.
A fascinating aspect of LLMs that has piqued the academic community’s interest is their method of concept representation. Traditionally, one might expect these models to employ intricate mechanisms to encode the nuances of language. However, observations reveal a surprisingly straightforward approach: concepts are often encoded linearly. The revelation poses an intriguing question: How do complex models represent semantic concepts so simply?
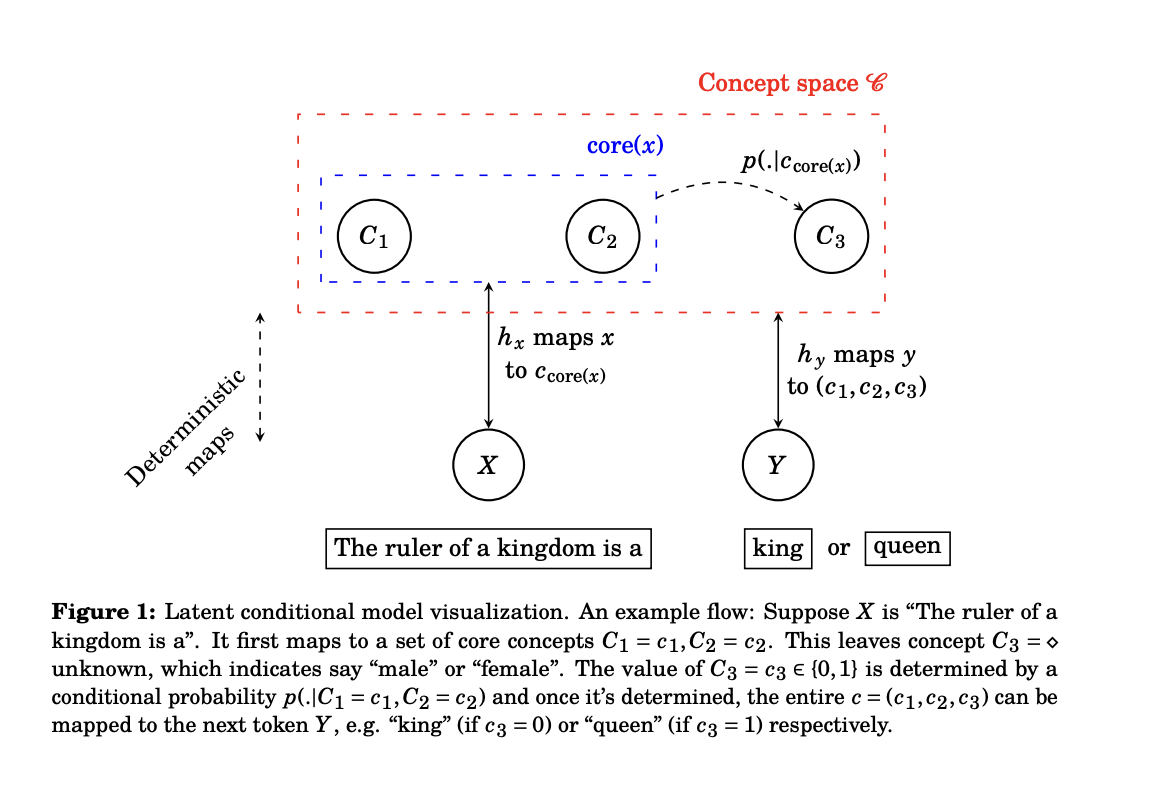
Researchers from the University of Chicago and Carnegie Mellon University have proposed a novel perspective to demystify the foundations of linear representations in LLMs to address the above-posed challenge. Their investigation pivots around a conceptual framework, a latent variable model that simplifies understanding of how LLMs predict the next token in a sequence. Through its elegant abstraction, this model allows for a deeper dive into the mechanics of language processing in these models.
The center of their investigation lies in a hypothesis that challenges conventional understanding. The researchers propose that the linear representation of concepts in LLMs is not an incidental byproduct of their design but rather a direct consequence of the models’ training objectives and the inherent biases of the algorithms powering them. Specifically, they suggest that the softmax function combined with cross-entropy loss, when used as a training objective, alongside the implicit bias introduced by gradient descent, encourages the emergence of linear concept representation.
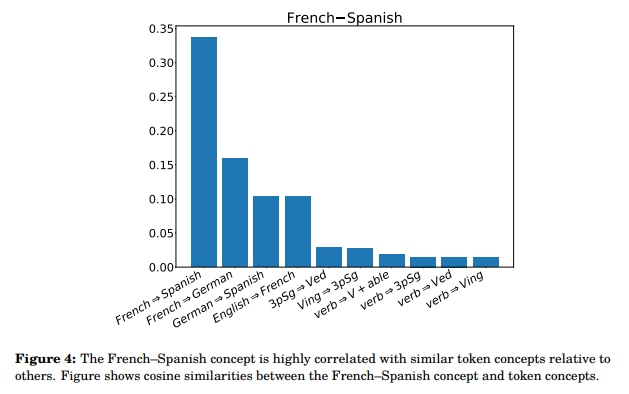
The hypothesis was tested through a series of experiments, both in synthetic scenarios and real-world data, using the LLaMA-2 model. The results were not just confirming; they were groundbreaking. Linear representations were observed under conditions predicted by their model, aligning theory and practice. This substantiates the linear representation hypothesis and sheds new light on the learning and internalizing process of language in LLMs.
The significance of these findings is that unraveling the factors that foster linear representation opens up a world of possibilities for LLM development. The intricacies of human language, with its vast array of semantics, can be encoded remarkably straightforwardly. This could potentially lead to the creating of more efficient and interpretable models, revolutionizing how we approach natural language processing and making it more accessible and understandable.
This study is a crucial link between the abstract theoretical foundations of LLMs and their practical applications. By illuminating the mechanisms behind concept representation, the research provides a fundamental perspective that can steer future developments in the field. It challenges researchers and practitioners to reconsider the design and training of LLMs, highlighting the significance of simplicity and efficiency in accomplishing complex tasks.
In conclusion, exploring the origins of linear representations in LLMs marks a significant milestone in our understanding of artificial intelligence. The collaborative research effort sheds light on the simplicity underlying the complex processes of LLMs, offering a fresh perspective on the mechanics of language comprehension in machines. This journey into the heart of LLMs not only broadens our understanding but also highlights the endless possibilities in the interplay between simplicity and complexity in artificial intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 38k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
You may also like our FREE AI Courses….
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.


