Introduction
Projected growth for the global intelligent document processing market is indeed impressive. It’s estimated to reach approximately $5.2 billion by 2027, expanding at an impressive compound annual growth rate (CAGR) of 37.5% from 2022 to 2027.
Unfortunately, traditional methods like manual processing or Robotic Process Automation (RPA) often fall short of efficiently handling documents. The diversity of document formats, the interpretation of natural language, and the presence of distortions often undermine the accuracy and productivity of these methods. This is where Intelligent Document Processing (IDP) shines.
IDP brings together the precision of RPA, the discerning eyes of Optical Character Recognition (OCR), and the cognitive power of Machine Learning (ML) to overcome these challenges. This combination enables IDP to learn and improve as it processes a larger volume of documents, leading to higher straight-through processing rates and freeing human teams to handle exceptions and more complex scenarios.
With the evolution of technology, the process of document management has transformed significantly, giving rise to Intelligent Document Processing (IDP), a crucial tool in the automation technology suite. This article delves into the intricacies of IDP, its workings, real-world applications, advantages, and challenges.
What is Intelligent Document Processing (IDP)?
Intelligent Document Processing (IDP) is a technology that utilizes artificial intelligence (AI) and machine learning to capture, extract, and interpret data from various types of documents. These documents may range from structured forms to unstructured data like emails and PDF files. IDP not only digitizes this information but also understands, categorizes, and makes it accessible for further use, thereby automating and optimizing business processes.
The fundamental difference between OCR and IDP lies in the outcomes. While OCR can process a limited portion of documents successfully – given that it works with machine-printed text and requires high-quality documents – its capabilities are somewhat restricted. In contrast, IDP can fully automate the processing of over 80% of documents, flagging a minimal number for human intervention. By integrating machine learning and natural language processing (NLP), IDP can process a wider variety of data, including semi-structured, unstructured, handwritten text, images, barcodes, stamp detection, and signature matching.
IDP shines particularly in areas such as email processing, compliance documentation, invoice processing, and claims processing. What makes these use cases ideal for IDP is their commonality – identifiable information and clear business rules. Users can train the IDP system to identify and route documents accurately, without the need for human review. This not only eliminates the need for manual data entry but also paves the way for full automation, transforming data processing from a chore into a strategic asset.
Its purpose? To capture, classify, and extract meaningful data from a corpus of documents a modern enterprise encounters daily.
How Does Intelligent Document Processing (IDP) Work?
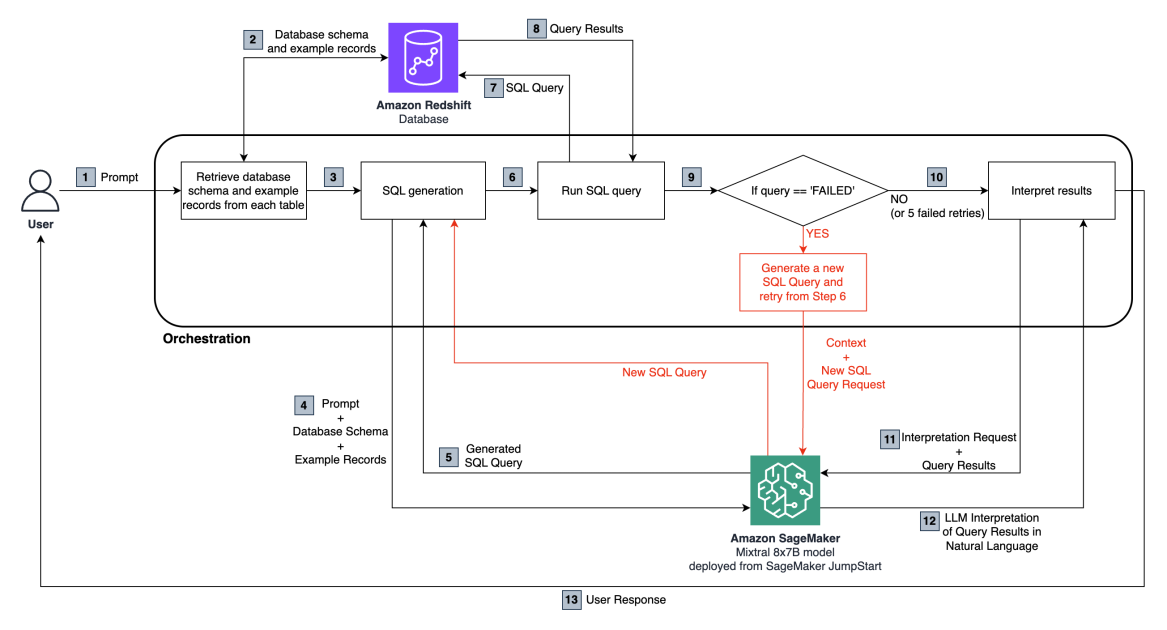
The Intelligent Document Processing (IDP) workflow is composed of several pivotal stages, each equipped with cutting-edge technologies to streamline the data processing pipeline. The diagram above outlines this process in a detailed and sophisticated manner, revealing the underlying technologies at each juncture.
Pre-Processing: The initial stage is pre-processing, where raw data undergoes a transformation into a machine-readable format. This is realized via Optical Character Recognition (OCR) technology. OCR acts as the backbone of the pre-processing phase, converting different types of data—be it scanned documents, PDFs, or images—into a format that can be understood and processed by subsequent stages of the workflow.
Classification: Following pre-processing, the classification phase is set into motion. The processed documents are segregated into distinct categories based on predetermined criteria. This segmentation is facilitated by the application of artificial intelligence (AI) and machine learning (ML) algorithms, which analyze the content and structural attributes of the documents, thereby ensuring their appropriate classification.
Extraction: After classification, the IDP system proceeds to the extraction stage. Here, the system retrieves relevant information from the classified documents, an operation powered by Natural Language Processing (NLP) technology. NLP equips the system with an understanding of the semantics and context of the text, enabling precise and accurate extraction of meaningful information.
Data Validation: Post-extraction, the system conducts data validation, a crucial step that confirms the accuracy and consistency of the data. This validation process is carried out using rules-based systems or ML models, which cross-verify the extracted information against specific standards or reference data.
At this juncture, the system evaluates the confidence score of the data validation output. Depending on the score, the data follows one of two paths. In the case of a high confidence score, the data proceeds directly to the output. However, a low confidence score diverts the data to the next stage—human review.
Human Review: Despite the advanced technologies powering IDP systems, there is still a need for human intervention in certain situations, particularly where the confidence score is low. Human review acts as a failsafe, ensuring the precision and reliability of the data before it is finalized for output.
Intelligent Document Processing Workflow

In the ever-evolving realm of technological advancement, Intelligent Document Processing (IDP) stands as a testament to the power of open-source tools. By providing a platform that’s both accessible and flexible, open-source tools act as catalysts in technological progression, particularly in the domains of Optical Character Recognition (OCR), Natural Language Processing (NLP), and ontology analysis.
Tesseract, an OCR system devised by Google, is a leading figure in this open-source landscape. Recognized for its ability to discern text within images and transcribe it into a machine-friendly format, Tesseract’s wide applicability and precision have earned it high regard among the scientific and programming communities focused on document processing.
Aiding Tesseract are several utilities that enhance text extraction from searchable PDFs. These tools supplement the understanding and interpretation of document data, opening avenues for automation and augmentation in a myriad of business operations. To further optimize this process, OpenCV—an acclaimed open-source library for computer vision and pattern recognition—bolsters OCR and text extraction functionality. By aiding in pre-processing tasks such as image refinement and segmentation, OpenCV improves the overall efficacy of OCR tools like Tesseract.

The landscape of machine learning has also been enriched by the rise of open-source libraries like TensorFlow/Keras and PyTorch. Offering a resilient framework for building and training machine learning models, these libraries are crucial in deciphering and processing unstructured and semi-structured data. Integrating these machine-learning libraries into IDP endeavors can significantly enhance the ability to navigate and comprehend complex documents, allowing for more accurate and efficient data extraction.
In the IDP workflow, the initial phase commences with document ingestion, where a variety of documents—regardless of their origin or format—are collated. The subsequent pre-processing stage involves tasks such as noise reduction, image enhancement, and orientation correction to prime the documents for further examination.
The extraction phase ensues, deploying OCR technology to identify and translate the text embedded within images into a machine-readable format. This is followed by the classification stage, where machine learning algorithms sort the documents based on various attributes, allowing for a more precise and efficient data extraction phase.
At this stage, vital information is sifted from the sorted documents, with techniques like Named Entity Recognition (NER) and NLP ensuring that no important data is missed. The workflow culminates in the validation and export phase, where the extracted data is checked for accuracy and then exported or integrated into downstream systems for subsequent analysis or action.
The introduction of advanced AI technologies, such as large language models (LLMs), has propelled document processing capabilities even further. Developed by organizations like OpenAI, LLMs like GPT-4 can comprehend and generate text akin to human capabilities, proving particularly beneficial for NLP tasks. The adaptability of LLMs, including the impressive ChatGPT, allows for the processing of documents with varying structures and styles, marking a significant progression from conventional OCR and text extraction methods.

ChatGPT 3, empowered by a staggering 175 billion machine learning parameters (GPT 4 rumoured to be around 100 trillion) , is a prime example of the potential of LLMs. Its ability to perform a spectrum of tasks—including translation, summarization, and question answering—is particularly advantageous in the IDP context, where understanding and manipulating text-based data is key.

In essence, the combination of open-source tools and sophisticated AI technologies provides IDP with an efficient, streamlined approach to data extraction and analysis. This capability to handle complex, unstructured data is revolutionizing how businesses manage documents, leading to increased productivity and facilitating data-driven decision-making.
Also Read: OCR Explained: A Guide to How OCR Technology Works
Real-World Applications of Intelligent Document Processing
Intelligent Document Processing, with its ability to manage and extract data from diverse and complex documents, has significant practical implications across a multitude of industries and sectors. Its applications extend from the automation of mundane tasks to decision-making processes fueled by in-depth data analysis.
In the healthcare sector, IDP tools can be used to digitize and manage patient records, lab reports, and other crucial documents. This not only streamlines record-keeping but also aids in predictive analysis, allowing healthcare professionals to anticipate patient needs and trends.
The finance and banking industry can also harness the power of IDP. The sector handles a massive volume of documents like invoices, receipts, contracts, and customer correspondence daily. Using IDP, these documents can be processed quickly and accurately, reducing the risk of manual errors, and speeding up the decision-making process. Fraud detection is another key application area, as IDP can swiftly spot suspicious patterns and anomalies within documents.
Legal firms and departments stand to gain from IDP as well. By automating the process of sorting and analyzing legal documents, IDP can reduce the workload of legal professionals, and expedite processes like contract analysis, litigation support, and due diligence.
In the field of education, IDP can assist in managing vast databases of academic resources, sorting them, and making them easily accessible for both teachers and students. It can also automate administrative tasks, such as processing student enrollments, maintaining attendance records, and evaluating exam scripts.
Advantages of Intelligent Data Processing
Intelligent Document Processing offers a range of advantages that contribute to its growing adoption in various industries.
Speed and efficiency top the list. By automating the extraction and processing of data, IDP significantly reduces the time taken to handle large volumes of documents. This is especially beneficial for organizations that regularly process large amounts of unstructured or semi-structured data.
Scalability is a crucial benefit of IDP. As businesses grow, so does their data. IDP systems can easily be scaled up or down to accommodate fluctuations in data volume, making them a cost-effective solution for data management.
The ability of IDP to work with various document formats and types is also noteworthy. Whether it’s a PDF, a scanned document, or even a handwritten note, IDP can handle them all. This versatility allows organizations to leverage data from diverse sources effectively.
Finally, IDP empowers businesses with actionable insights. By extracting and organizing data from unstructured and semi-structured documents, IDP allows organizations to better understand their operations, make informed decisions, and ultimately drive their growth and success.
Top IDP SaaS Companies
In 2023, there are several trailblazers in the Intelligent Document Processing (IDP) Software as a Service (SaaS) landscape. Here’s a glimpse into a few of them:
CognitiveScale, a leader in AI-powered solutions, recently caught the eye with their acquisition by Tecnotree. They’re using this partnership to fuel AI-powered 5G monetization on a global scale. They’ve also got an impressive portfolio of over 100 AI-specific patents1.
Kofax, a powerhouse in intelligent automation platforms, has recently revamped the Kofax Marketplace. This digital hub is a treasure trove of apps, connectors, tools, and templates designed to enhance the integration of leading business and automation software.
Nuance Communications, now a part of the Microsoft family, has made waves with the announcement of Dragon Ambient eXperience (DAX™) Express. This innovative tool is the first of its kind, merging conversational and ambient AI with OpenAI’s latest GPT-4 model to provide a fully automated clinical documentation application.
OpenText is another notable player, having recently acquired Micro Focus, a provider of mission-critical software technology. They’re also a recognized leader in content platforms as per the Forrester Wave.
Salesforce, the global CRM leader, reported $7.4 billion in revenue in the first quarter of fiscal 2023, marking a 24% growth year-over-year. It’s clear they’re not slowing down any time soon.
These companies offer a variety of IDP solutions, each tailored to a specific industry or use case. For example, CognitiveScale offers a solution for healthcare organizations, while Kofax offers a solution for financial services organizations.
Also Read: Can AI Write the Dictionary? Does AI Know What Words Mean?
How IDP SaaS Companies Work
IDP SaaS companies use a variety of technologies to automate the document processing process. These technologies include:
- Optical Character Recognition (OCR)
- Natural Language Processing (NLP)
- Machine Learning (ML)
- Artificial Intelligence (AI)
OCR is used to convert scanned documents into text. NLP is used to understand the meaning of the text in a document. ML is used to train IDP models to extract data from documents. AI is used to provide insights into the data extracted from documents.
Why You May Use an IDP SaaS Company
IDP SaaS companies can offer a number of benefits to businesses. These benefits include:
- Increased efficiency: IDP SaaS companies can automate the manual tasks associated with document processing, freeing up employees to focus on more strategic work.
- Improved accuracy: IDP SaaS companies can reduce the risk of human error by automating the data extraction process.
- Reduced costs: IDP SaaS companies can help businesses save money on labor costs and other expenses associated with document processing.
- Improved compliance: IDP SaaS companies can help businesses comply with regulations by automating the data extraction process.
- Gained insights: IDP SaaS companies can help businesses gain insights into the data extracted from documents, which can be used to make better decisions.
If you are looking for a way to automate the document processing process, improve the accuracy of the document processing process, reduce the cost of the document processing process, improve compliance with regulations, or gain insights into the data extracted from documents, then you may want to consider using an IDP SaaS company.
Overcoming IDP Challenges: Tagging, Standardization, and Synergy with RPA
The journey of Intelligent Document Processing (IDP) is filled with both incredible opportunities and daunting challenges. Among these challenges, document tagging, standardization of processes, and the integration of IDP with Robotic Process Automation (RPA) stand out. This section will delve into these issues, revealing their complexities and exploring potential solutions.
Document Tagging
One of the primary obstacles in IDP is document tagging. This process involves labeling or classifying documents based on their content, structure, or other defining attributes. This task becomes difficult, primarily due to the vast variety of document types and formats that businesses deal with. The information extracted from these documents greatly depends on effective tagging, as it determines how the subsequent steps of the IDP workflow, such as data extraction and validation, will take place.
There’s also the issue of the dynamic nature of documents. Documents change and evolve over time, both in terms of their content and format. Consequently, a tagging system that works effectively today might not be as efficient tomorrow. Thus, the challenge lies in creating a flexible and adaptable tagging system that can keep up with these changes.
Automated Machine Learning (AutoML) could be a potential solution for this issue. By employing techniques like clustering, it can automate the document tagging process, while being capable of adapting to new types of documents.
Standardization
Standardization of IDP processes is another crucial challenge. Different businesses use varied document types and follow unique processes. Thus, creating a one-size-fits-all solution is practically impossible. In addition, the task of extracting data and deriving value from it varies considerably across organizations and industries.
In light of this, it becomes essential to implement customized solutions that cater to specific business needs. However, developing such bespoke solutions often requires significant time and resources. One potential solution is to adopt a modular approach to IDP. This means developing an IDP system with interchangeable components that can be replaced or modified according to specific business needs, thereby facilitating a level of standardization without compromising on customization.
IDP and RPA Synergy
Finally, the integration of IDP with Robotic Process Automation (RPA) presents its own set of challenges. While the synergy of these two technologies holds immense potential, the path to integration is not straightforward.
RPA excels at automating repetitive tasks that follow a set of rules. However, its efficiency drops when it comes to handling unstructured or semi-structured data, a domain where IDP shines. Therefore, integrating IDP with RPA to handle complex, unstructured data appears to be a logical step.
However, the issue arises when we consider the variations in data structures and formats, as well as the evolution of these parameters over time. The challenge, therefore, lies in creating a flexible and adaptable system that seamlessly blends the capabilities of IDP and RPA, allowing them to complement each other effectively.
The adoption of technologies such as AI and machine learning can be instrumental in this regard. These technologies can learn and adapt to changes in data structures and formats, enhancing the flexibility of the integrated system.
Conclusion
The astonishing surge of the IDP market paints a compelling picture of a future where businesses are no longer bogged down by stacks of paper or a deluge of digital files. But rather, they’re moving towards a future where the processing of documents is as easy as a snap of the fingers.
Yes, there are hurdles to jump over – standardization, document tagging, and synergizing IDP with RPA. But let’s not forget, we’re in an era where the likes of Tesseract and OpenCV are harnessing the power of open-source tools, and GPT-4 is pushing the boundaries of large language models. With such technological might, these challenges aren’t insurmountable but stepping stones towards a future where IDP rules the roost.
Also Read: What is Reverse ETL (Extract, Transform, and Load) and What is it Used For?
References
Anywhere, Automation. “What Is Intelligent Document Processing – (IDP)?” Automation Anywhere, 30 Jan. 2021, https://www.automationanywhere.com/rpa/intelligent-document-processing. Accessed 26 May 2023.
Free OCR API V2023, Online OCR, Searchable PDF Creator, On-Premise OCR Software. http://ocr.space/. Accessed 26 May 2023.
“Intelligent Document Processing with Small and Relevant Training Dataset.” IEEE Xplore, https://ieeexplore.ieee.org/document/9806100. Accessed 26 May 2023.
Peak, Team High. “The Beginner’s Guide To Intelligent Document Processing (IDP).” Becoming Human: Artificial Intelligence Magazine, 11 Mar. 2020, https://becominghuman.ai/the-beginners-guide-to-intelligent-document-processing-idp-5cc88b8de425. Accessed 26 May 2023.
“What Is Intelligent Document Processing (IDP)?” Microsoft Power Automate, https://powerautomate.microsoft.com/en-us/intelligent-document-processing/. Accessed 26 May 2023.
“What Is Intelligent Document Processing(IDP)? – Benefits and Use-Cases of IDP in Different Industries.” Use-Cases and Benefits of IDP in Different Industries, https://www.docsumo.com/blog/intelligent-document-processing-idp. Accessed 26 May 2023.